
此文包含较多图片,加载时间可能较长,请耐心等待:)
- 目录
- Dynaslam: Tracking, mapping, and inpainting in dynamic scenes (2018 IEEE RAL)
- Mask-SLAM: Robust feature-based monocular SLAM by masking using semantic segmentation (2018CVPR)
- MaskFusion: Real-Time Recognition, Tracking and Reconstruction of Multiple Moving Objects (2018ISMAR)
- Slam++: Simultaneous localisation and mapping at the level of objects (CVPR2013)
- DS-SLAM: A Semantic Visual SLAM towards Dynamic Environments (IROS2018)
- Probabilistic Data Association for Semantic SLAM (ICRA2017)
- Light-weight refinenet for real-time semantic segmentation (BMVC2018)
- Real-Time Joint Semantic Segmentation and Depth Estimation Using Asymmetric Annotations (ICRA2019)
- Stereo Vision-based Semantic 3D Object and Ego-motion Tracking for Autonomous Driving (ECCV2018 港科大)
- Stereo R-CNN based 3D Object Detection for Autonomous Driving (CVPR2019 港科大)
- Long-term Visual Localization using Semantically Segmented Images (ICRA2018)
- A variational feature encoding method of 3d object for probabilistic semantic slam(IROS2018)
- Detect-SLAM: Making Object Detection and SLAM Mutually Beneficial (2018WACV)
- SIVO : Semantically Informed Visual Odometry and Mapping (硕士论文, 2018, University of Waterloo, Canada,Pranav Ganti)
- 其他相关论文
Dynaslam: Tracking, mapping, and inpainting in dynamic scenes (2018 IEEE RAL)
OpenSource
Lab
Universidad de Zaragoza(萨拉戈萨大学,西班牙)
Content
结合Mask-RCNN和ORN-SLAM2建立了一套动态场景SLAM系统,包含单目、双目和RGB-D三种输入。整个开源算法较有价值的部分:使用C++代码调用MaskRCNN模型(Python3+Keras,作者实现比较粗糙),RGBDSLAM中使用SLAM结果来优化MaskRCNN的结果。
单目:最简单的情形。使用Mask-RCNN在COCO数据集上训练的模型对图像进行语义分割,训练得到的模型一共可分辨81个类别,取其中的19个(人、自行车、飞机、鸟等)作为移动物体,将从这些移动物体区域中提取的ORB特征删除,不让其进入ORB-SLAM的处理流程中。
双目:和单目一样。
RGB-D:在单目SLAM的基础上增加了两个功能:使用多视几何方法来辅助图像语义分割;填补被运动物体遮挡的背景。
第一个功能的效果图如下(其中被人拿着的书本和被人坐着的椅子被多视几何方法识别出来了):

方法:选取与当前帧 $F_{cur}$ 具有最高重合度的关键帧 $F$ (使用两帧间的相对运动来判断),计算 $F$ 中ORB特征点点 $x$ 在当前帧中的投影深度 $z_{proj}$ , $x’$ 是 $F_{cur}$ 中 $x$ 的对应点, 它的深度为 $z$ (由RGBD数据直接获得), 如果 $z-z_{proj}$ 超出了特定阈值,表明这个点是个移动物体上的点。以上方案的结果就是多视几何获取的运动物体,参见上面的左图。将两种方法获取的结果做融合:两种方法检测到的相同物体,以多视几何的为准,各自检测到的直接加到最终结果中。
第二个功能的效果图如下(第一列是输入的图像,第二列是去除了运动物体之后的图像)

方法:对于当前帧 $F_{cur}$ ,将一组关键帧(20帧)的图像投影到 $F_{cur}$ 中动态物体的区域,通过检测这些点的深度一致性来判断能不能把图像补上,一致的就使用之前关键帧的图像来补图。
系统结构(虚线是RGBD-SLAM的数据流):

实验结果:
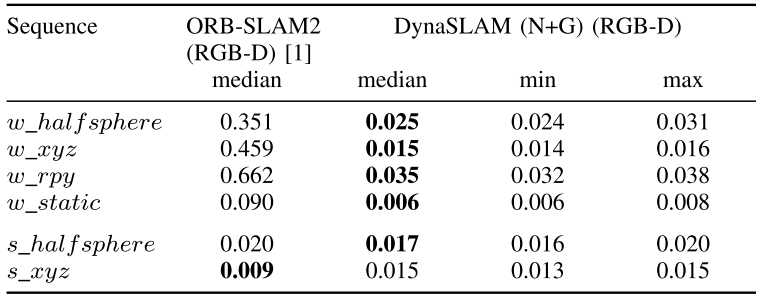
总结
- 在动态场景中机器学习方法去除运动部分确实有用;
- 目前的方法计算时间过长(MaskRCNN就需要195ms来处理一帧,Tesla M40);
- 补图可以提高重建能力,但对位姿精度没有帮助。
Mask-SLAM: Robust feature-based monocular SLAM by masking using semantic segmentation (2018CVPR)
OpenSource
无
Lab
The University of Tokyo(东京大学)
Content
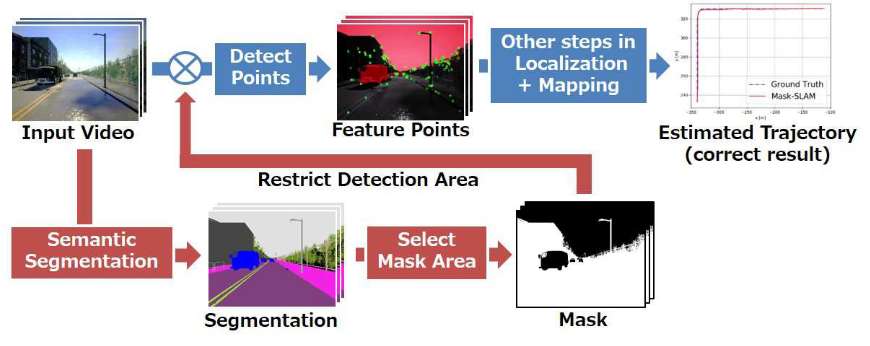
目前的SLAM算法大多只能处理非动态场景,当场景中存在动态物体或者其他不适合vSLAM处理的部分(如天空)时,现有算法使用RANSAC来剔除这些区域,但是前提是动态物体在整个场景中占少数,当场景中多数部分为动态时,现有算法无法处理,本文结合语义分割算法来处理这样的场景。
基于ORB-SLAM2,使用已有的语义分割算法:DeepLab v2。
DeepLab v2:”DeepLab: Semantic Image Segmentation with Deep Convolutional Nets” arXiv, 2016. [1]
本文只关注汽车和天空,只剔除图像中这两类物体的区域。
创新点:
- 将现有vSLAM系统与语义分割神经网络算法结合,解决以上问题;
- 由于现有的KITTI等数据集中环境仍然太过理想,使用CARLA模拟器(”CARLA: An Open Urban Driving Simulator”2017)新造了个数据集。
系统结构(和DynaSLAM中单目系统一样):
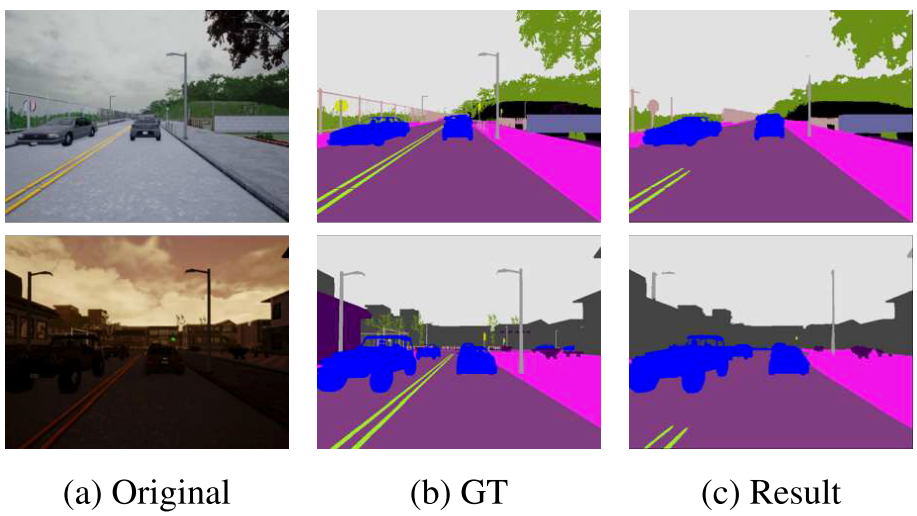
由于新造的这个数据集有地图真值,其中包含13类语义标签:“None,” “Buildings,” “Fences,” “Other,” “Pedestrians,” “Pole,” “Roadlines,” “Roads,” “Sidewalks,”“Vehicles,”“Walls,” and“Trafficlights”(其中的None被认为是天空),所以可以直接让DeepLab v2在这个数据集上训练,然后用相同场景来做测试,有一定优势,DeepLab v2分割出的结果:
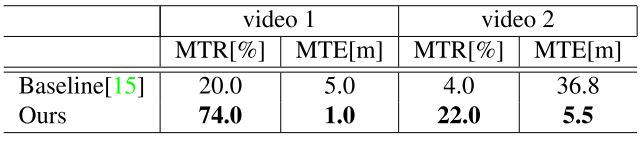
实验结果(其中MTR:Mean Tracking Rate,越高越好,MTE:Mean Trajectory Error,越低越好):
总结
- 和DynaSLAM一样,属于vSLAM结合语义的初步工作;
- 未给出运行时间,但文中说了现在不是实时系统,需要进一步的工作。
MaskFusion: Real-Time Recognition, Tracking and Reconstruction of Multiple Moving Objects (2018ISMAR)
OpenSource
Lab
University College London(伦敦大学学院)
Content
提出了一个结合语义分割的RGBD-SLAM,它有这样的功能:传统SLAM功能(跟踪相机位姿,建立三维地图),能够区分场景中的动态物体并识别它们的语义标签(比如玩具熊),能够跟踪环境中的动态物体(即分析它们的位姿)并建立这些动态物体的三维模型
相比于其他类似系统,本文系统有以下几个优势:
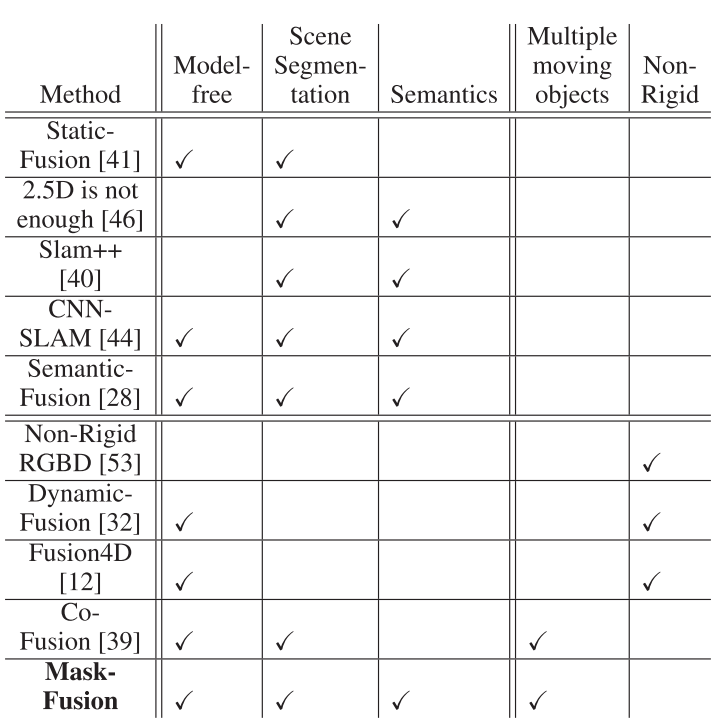
说明:
- Model Free:能否做到不需要提前知晓待分割物体的三维模型;
- Scene Segmentation: 是否具有场景分割能力;
- Semantics: 分割的场景中是否包含语义标签;
- Multiple moving objects: 对于同一类物体(比如车),是否可以分辨其中的不同对象(车1,车2)。这个能力实际上是MaskRCNN提供的。
- Non-Rigid: 是否具有对环境中非刚体物体的处理能力。
所对比的系统:
- StaticFusion: Background reconstruction for dense RGB-D SLAM in dynamic environments. (2018ICRA) [41]
- When 2.5d is not enough: Simultaneous reconstruction, segmentation and recognition on dense slam. (2016ICRA) [46]
- Semanticfusion: Dense 3d semantic mapping with convolutional neural networks. (2017ICRA) [28]
- Real-time non-rigid reconstruction using an rgb-d camera. ACM Trans. Graph. 2014 [53]
- Dynamicfusion: Recon- struction and tracking of non-rigid scenes in real-time. (2015CVPR) [32]
- Fusion4d: Real-time performance capture of challenging scenes. ACM SIGGRAPH 2016. [12]
- Co-fusion: Real-time segmentation, tracking and fusion of multiple objects. (2017ICRA). [39]
地图表示
地图中保存的是一个个独立的三维模型,这些三维模型使用面元(surfel)集合表示,一个surfel包含位姿、法向量、颜色、权重、直径和两个时间戳(position, normal, colour, weight, radius and two timestamps)参数,同时,这些模型还对应一个分类ID(共80个,表示语义)和一个对象ID(同一语义类别可以有多个对象)
跟踪过程
两个步骤:数据关联、位姿优化。
数据关联:将地图中的三维模型与当前帧内的RGBD图像区域关联起来。最简单的思路是先将图像中的物体分割出来,然后一个个去对应地图中的物体模型。以上步骤中的图像分割过程存在这样的问题:MaskRCNN分割太慢,几何分割很快但没有语义标签,如何同步?这部分相对复杂,在论文中是一个单独章节,参考下面的图像分割章节。
位姿优化:每个模型对应两个数据结构:深度图(三维)和光度图(二维),基于当前帧位姿将这两个数据从世界坐标系投影到当前帧,可以得到深度误差和光度误差。由此,可以得到位姿优化过程中的代价函数:
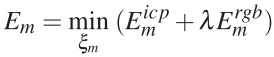
以上公式中具体两项的计算较为简单,核心是投影过程:将三维点投影到当前帧坐标系,与当前帧对应三维点(输入的RGBD数据得到)的距离差值即为前者误差,后者为二维投影得到的二维点的光度误差,这部分使用GPU实现,实现代码参考论文[50]和[39]。
- ElasticFusion: Dense SLAM without a pose graph. (2015RSS) [50]
- Co-fusion: Real-time segmentation, tracking and fusion of multiple objects. (2017ICRA) [39]
图像分割
几何分割:基于这样的假设:三维空间中独立物体大多具有凸面,而且这些物体之间的深度是不连续的。即通过以上假设来把物体边缘识别出来,但是这个方法也很容易得到过度分割的结果。本文使用了论文[45]中的方法。每一个像素对应两个数值项:一个是用与临近点之间的法向量点积表示的凹面边缘(表示两个凸面之间的位置),另一个是用临近点之间的距离差值表示的深度连续程度,这两个值的加权和大于阈值时表明这个点是物体边缘:
\[\phi_d+\lambda\phi_c > \tau\]得到这些边缘点之后,使用连通域(connected components)算法即可求出图像中物体的分割结果。
- Real-time and scalable incremental segmentation on dense slam. In IEEE/RSJ International Conference on Intelligent Robots and Systems, 2015 [45] 源代码
每一帧图像都进行几何分割处理,在得到了较慢的语义分割算法结果之后,融合语义分割和几何分割,前者耗时长、分割的边缘往往不准确,后者快速,但常常出现过度分割(tends to oversegment objects)。融合两者的好处:系统可以实时运行(几何分割),可以获得分割部分的语义(语义分割)。这个方法来自论文[23]和[50]
- Real-time 3d reconstruction in dynamic scenes using point-based fusion. 3DV 2013 [23]
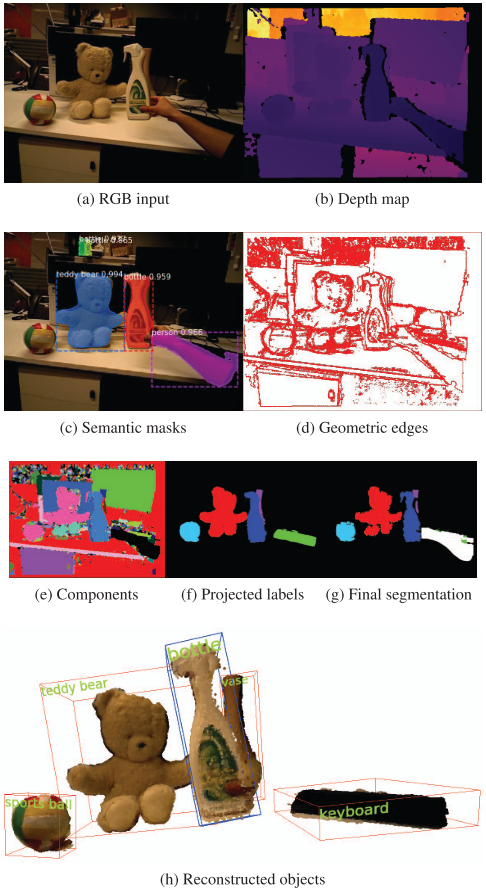
融合步骤:当语义分割没有执行完的时候,几何分割的结果直接与地图中的模型进行关联(使用投影面积重合率来关联),之后进行位姿优化;语义分割结束时,几何分割结果先与语义分割的结果进行关联(重合率),然后融合,融合结果接着与前几帧中的图像分割结果关联,然后与地图中使用OpenGL渲染过的模型进行关联。融合效果:
实验:
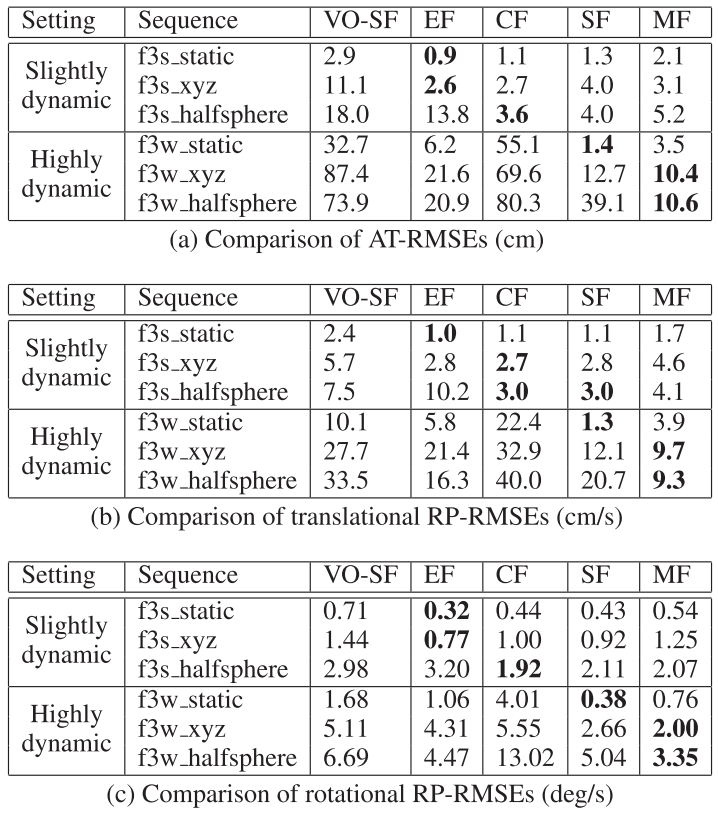
- 数据集:TUM
- VO-SF:Fast odometry and scene flow from rgb-d cameras based on geometric clustering (2017CIRA) [21]
- ElasticFusion EF:ElasticFusion: Dense SLAM without a pose graph (2015RSS) [50] 源代码
- CF:Co-fusion: Real-time segmentation, tracking and fusion of multiple objects (2017ICRA) [39]
- SF:StaticFusion: Background reconstruction for dense RGB-D SLAM in dynamic environments [41]
- MF:本文算法
定位精度(EF和其他算法效果为啥好:可能其他分类为动态或者外点的部分也对跟踪过程有帮助):
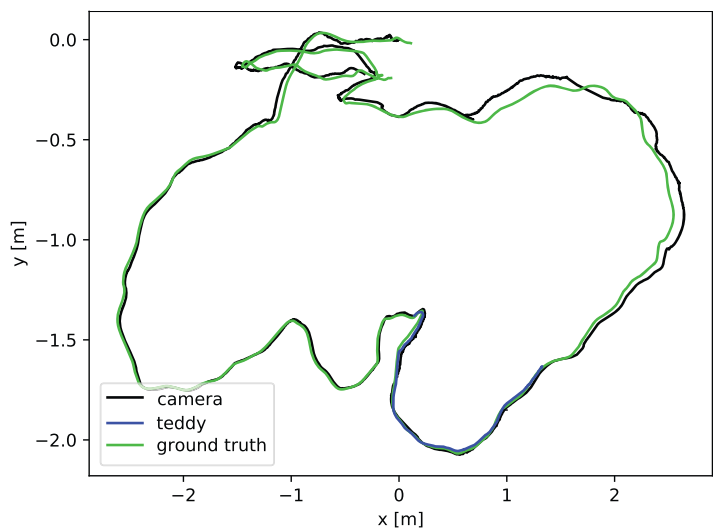
在TUM场景中泰迪熊和相机的移动轨迹(说明泰迪熊会对计算引入较大误差,不区分它的结果中绝对轨迹误差的RMSE增加了7.2cm):
应用示例:
AR应用1:虚拟物体可以与环境中的动态物体进行互动:

AR应用2:使用语义地图后可以完成食物卡路里的分析

总结
- SLAM系统同时输出相机位姿和场景中运动物体位姿这个功能对于AR应用来说具有很大价值;
- 系统实时性还有较大问题,系统需要两块GPU(实验平台:2 * Nvidia GTX Titan X),一块做语义识别(MaskRCNN),一块用于SLAM中的几何分割和模型渲染(OpenGL)。当环境中没有运动物体时系统速度为30Hz,当有三个运动物体模型时系统性能下降至20Hz。但目前看来,是为数不多的几个能达到实时的语义SLAM。
Slam++: Simultaneous localisation and mapping at the level of objects (CVPR2013)
OpenSource
无
Lab
Imperial College London(帝国理工学院)
Content
提出了一个RGBD-SLAM系统,该系统具有具备先验知识,先验知识可以重复性地呈现,使得实时3D重建和简单的关于物体位置的图优化地图成为可能。
首先需要对环境中常见的三维物体进行建模(使用mesh表示),使用KinectFusion方法。SLAM运行时其地图中的数据为数据库内的三维模型及其位姿。
过程:物体识别、数据关联、位姿优化、物体表面重建。
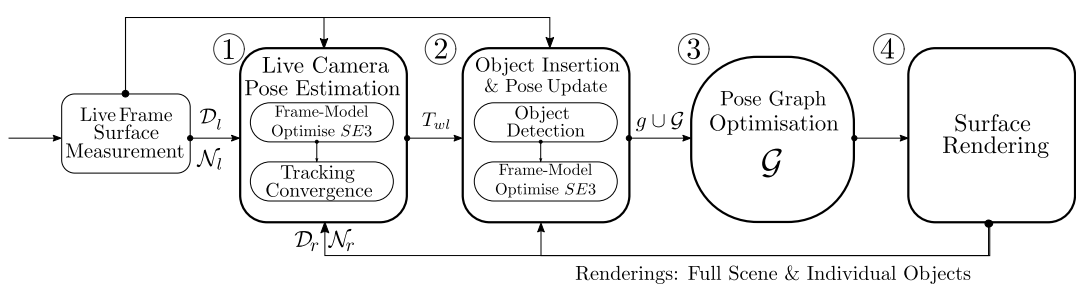
系统结构:
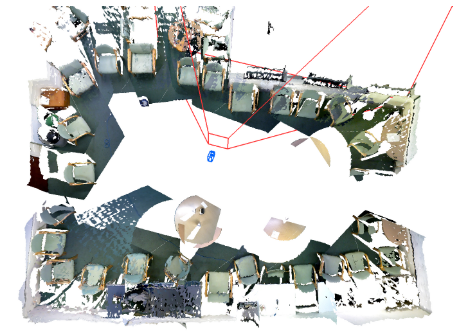
建图效果:
DS-SLAM: A Semantic Visual SLAM towards Dynamic Environments (IROS2018)
OpenSource
Lab
清华大学,北京航空航天大学
Content
本文贡献:
- 基于ORB-SLAM2提出了一个更适于处理动态场景的SLAM系统,在TUM RGBD数据集和真实场景中进行了实验;
- 实现了一个独立线程中运行的、实时的语义分割网络;
- 能够建立一个稠密的语义地图,地图用Octo-Tree表示,Octo-Tree来自论文[8].
- OctoMap: an efficient probabilistic 3D mapping framework based on octrees (Autonomous Robots 2013) [8]
系统结构较为简单,如下图所示,系统包含五个线程,除了通用的Local Mapping、Tracking、Loop Closing之外,还包含了语义分割(Sementic Segmentation)线程和稠密地图重建(Dense Map Creation)线程。
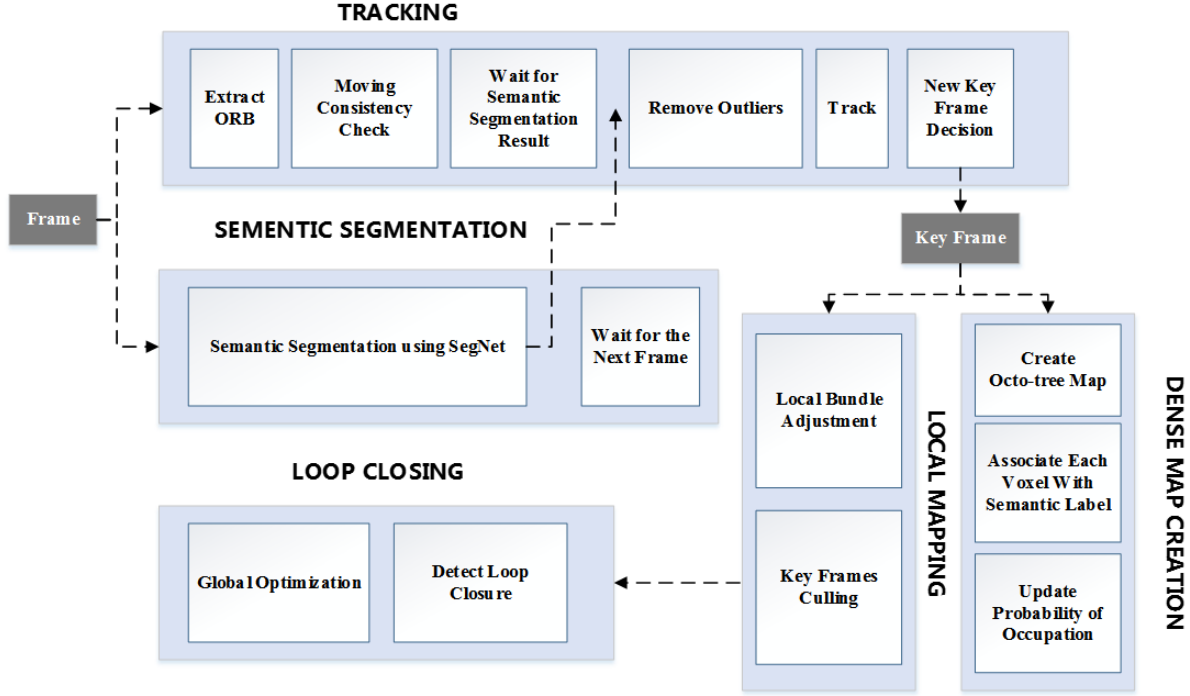
重点讲述多出来的两个线程和这两个线程与其他线程之间的交互。
语义分割线程:使用SegNet网络 (“Segnet: A deep convolutional encoder-decoder architecture for image segmentation” 2015 Arxiv),在PASCAL VOC (“The pascal visual object classes (voc) challenge” 2010)数据集上训练,可以得到像素点的关联语义,共由20个语义类别。此线程与Tracking线程交互,每一帧都同时输入以上两个线程,Tracking线程等待语义分割线程的结果并对分割结果中物体运动与否进行判断,这算文中的一个核心创新,但比较简单:使用对极约束,点到对应点极线的距离大于阈值时,认为此点为移动点,这个步骤作者称为运动一致性检测 (moving consistency check),如果语义分割的结果中某个物体对应的移动像素点数目超出阈值,则认为此物体是移动物体。位姿优化时不使用这些像素点。反之则丢弃语义分割的结果。
稠密地图重建线程:使用论文[8]中的方法,利用地图中的关键帧来产生稠密点云,然后将点云转化为论文[8]中描述的octo-tree形式,octo-tree地图是由一个个体素(voxel)组成的,参见下图。每个体素关联到了某一个物体语义上(属于桌子、椅子等),体素是否属于某一个语义类别由概率 $p \in [0,1]$ 表示,这个概率的传播过程使用logit模型(与论文[8]中相同),概率 $p$ 对应语义关联事件的 $Odds$ 为 $\frac{p}{1-p}$ , $Odds$ 的对数为 $L = log(\frac{p}{1-p})$ ,[8]中称其为 $log Odds$ 分数, $L$ 和 $p$ 可以很容易地相互转换,$L$ 的传播描述为 $L_{t+1} = L{t-1} + L{t}$ ,其中 $t$ 为时间,这样就能够让体素与语义的关联概率得到更新(从 $L$ 可以求出 $p$ ),可以看出体素被观测到的次数越多,概率 $p$ 就越大,观测的次数变少,概率 $p$ 就会变小。

实验结果
在TUM RGBD数据集的fr3_walking_xyz场景下的APE和RPE:
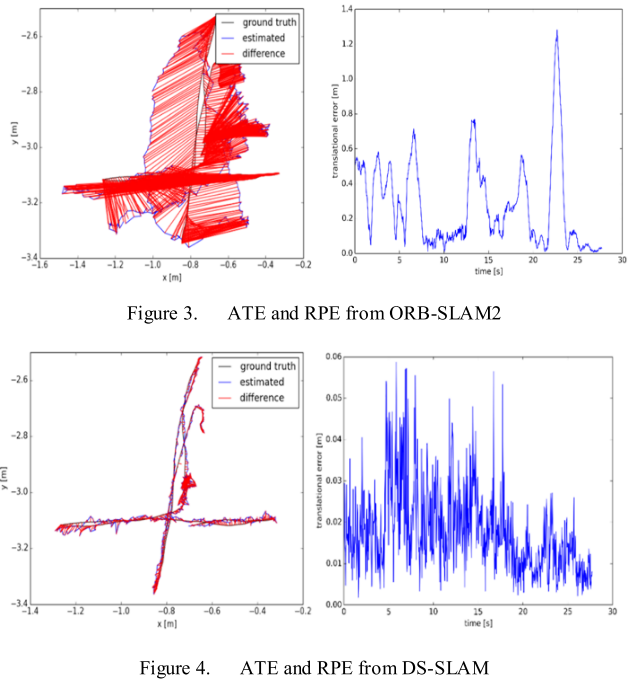
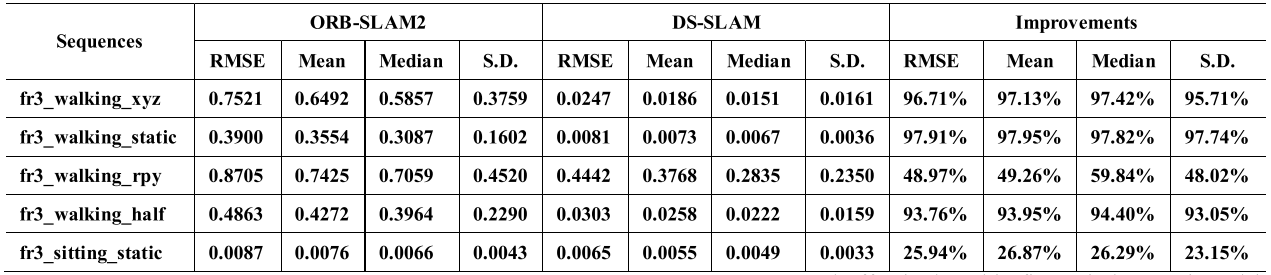
量化对比结果(ATE):
总结
- 本文系统能够实时运行(在Quadro P4000下运行速度为59.4ms每帧),这得益与SegNet的选择(相对于MaskRCNN 150~200ms每帧的速度,SegNet 每帧仅需37.57ms),个人觉得目前的SLAM+语义不需要那么多语义类别(MaskRCNN 80类,SegNet 20类),因为瞄准于动态场景的这类系统的目标就是为了提升SLAM位姿计算精度,要那么多类别干什么,如果是为了实现语义地图,辅助上层应用,要应该归为另外的类别,比如MaskFusion这种;
- 个人感觉如果语义分割只在关键帧上进行,而语义标签可以依靠关键帧传递给普通帧,那么
Probabilistic Data Association for Semantic SLAM (ICRA2017)
2017ICRA最佳会议论文
OpenSource
无
Lab
University of Pennsylvania(宾夕法尼亚大学)
Content
本文构建了一个基于IMU数据和图像语义分割结果、特征提取结果分析相机位姿和路标点位姿、语义信息的SLAM系统。
数学描述:给定IMU传感器数据 $I\in{I_t}{t=1}^T$ ,图像上的二维点数据 $y\in{y_t}{t=1}^T$ ,语义标签 $S\in{S_t}_{t=1}^T$ ,分析传感器位姿轨迹 $X$ 和地图中路标点 $L$ 的位置和语义属性。
核心创新点:将数据关联引入SLAM的优化过程中,同时完成地图中路标点的位置优化、语义关联和相机位姿优化。
通用的SLAM问题数学建模(最大后验概率估计,MAP):
\[\hat{X},\hat{L}=\mathop{argmax}_{(X,L)}\log p(Z|X,L)\]这其中略掉了一项:观测值与路标点的数据关联 $D=(l_k,z_k)_{k=1}^K$ ,因为在常见的SLAM系统中,以上数学表达的示例为三维特征与图像二维特征的对应关系,一般使用几何或图像描述子的方法得到,无需在优化过程中完成这一数据关联。而这一方案存在一些缺陷:
- 一次重投影或者描述子匹配没有关联上的路标点就会被直接丢弃,不再参与优化过程;
- 错误关联没有更正的机会。
本文构建的SLAM系统的数学表达如下,即将数据关联过程集成到优化过程中,在EM等类似算法的处理过程中迭代地寻找较优的关联关系和其他变量的值。
\[\hat{X},\hat{L},\hat{D}=\mathop{argmax}_{(X,L,D)}\log p(Z|X,L,D)\]为了便于求解,基于坐标下降(coordinate descent)法(迭代优化,每次只优化一个分量),将以上优化问题分解为两个迭代求解的问题:
\[D^{i+1} = \mathop{argmax}_{D}\log p(D|X^i,L^i,Z)\] \[X^{i+1},L^{i+1} = \mathop{argmax}_{X,L}\log p(Z|X,L,D^{i+1})\]作者认为以上方法仍然需要一个先验的 $D$ (类似传统SLAM算法中数据关联的结果),如果能在优化过程中包含所有可能的关联关系,优化算法得到的结果无疑会更准确。作者基于EM方法使用如下误差函数:
\[X^{i+1},L^{i+1} = \mathop{argmax}_{X,L}\mathbb{E}_D[\log p(Z|X,L,D) | X^i,L^i,Z]\] \[X^{i+1},L^{i+1} = \mathop{argmax}_{X,L}\sum_{D \in \mathbb{D}}p(D|X^i,L^i,Z)\log p(Z|X,L,D)\]其中 $\mathbb{D}$ 为 $D$ 的全部取值空间(即所有可能的数据关联),这样上述误差函数中就不需要认为指定先验的 $D$ 了。
Light-weight refinenet for real-time semantic segmentation (BMVC2018)
OpenSource
Lab
University of Adelaide(阿德莱德大学,澳大利亚)
Content (部分解读来自网络)
文章目的:在CVPR2017的RefineNet语义分割算法基础上减少模型参数和计算量。
- RefineNet: “Refinenet: Multi-path refinement networks for high-resolution semantic segmentation” (2017CVPR 开源代码)
RefineNet:使用经典的编码器-解码器架构,CLF为3*3卷积,卷积核个数为语义类的个数,编码器的骨干网可以是任意图像分类特征提取网络,重点是解码器部分含有RCU、CRP、FUSION三种重要结构。
本文改进方案:
RefineNet原始网络:
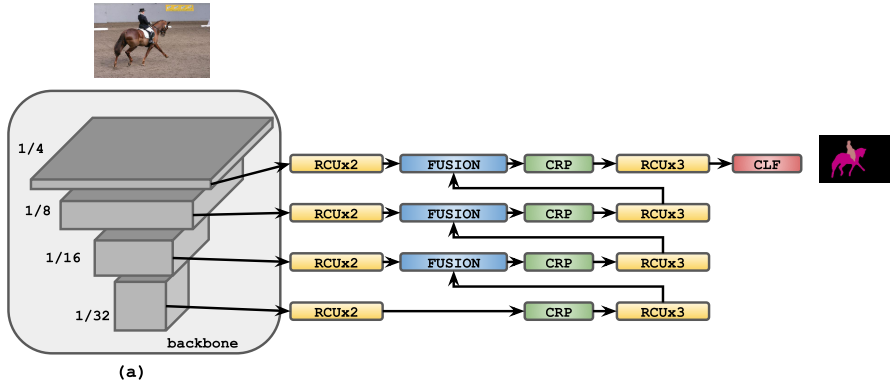
网络中的residual convolutional unit (RCU)、chained residual pooling (CRP)和fusion模块(CLF:a single 3x3 convolutional layer):
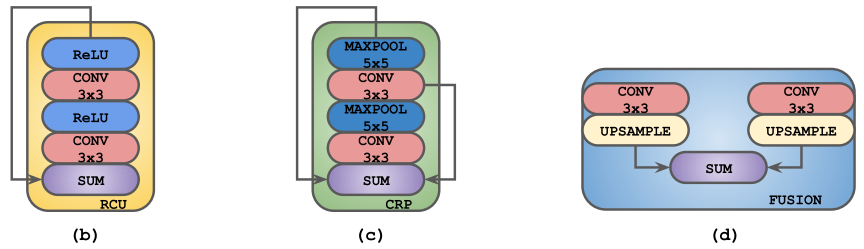
改进后的模块:
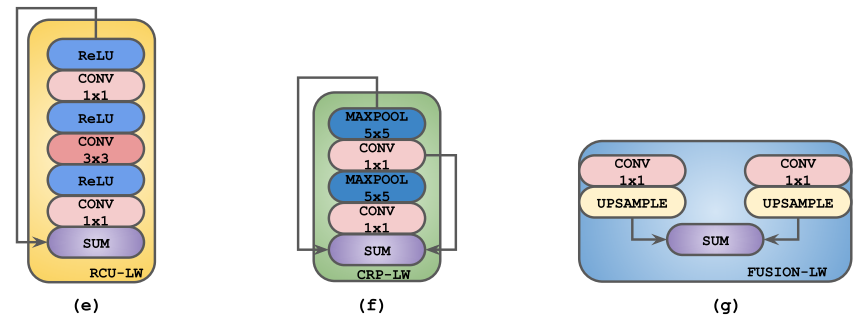
- 替换3x3卷积为1x1卷积。虽然理论3x3卷积理论上有更大的感受野有利于语义分割任务,但实际实验证明,对于RefineNet架构的网络其并不是必要的。
- 省略RCU模块。作者尝试去除RefineNet网络中部分及所有RCU模块,发现并没有任何的精度下降,并进一步发现原来RCU blocks已经完全饱和。
- 使用轻量级骨干网。作者发现即使使用轻量级NASNet-Mobile 、MobileNet-v2骨干网,网络依旧能够达到非常稳健的性能表现,性能不会大幅下降。
实验结果
在NYUDv2 和 PASCAL Person-Part数据集上,虽性能略有下降,但参数量和计算时间大幅降低。同时作者也在PASCAL VOC数据库上进行了实验,并加入NASNet-Mobile 、MobileNet-v2骨干网,发现对比于使用相同骨干网路的目前几乎是最先进的语义分割架构DeepLab-v3,RefineNet-LW的性能表现更具优势。
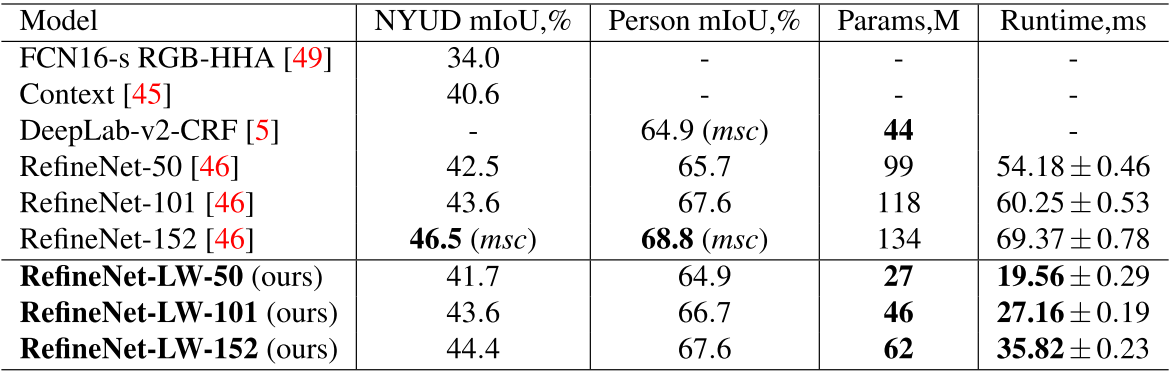
mIoU:平均交并比(真正样本数量/(真正样本数量+假负样本数量+假正样本数量))
Real-Time Joint Semantic Segmentation and Depth Estimation Using Asymmetric Annotations (ICRA2019)
OpenSource
Lab
University of Adelaide(阿德莱德大学,澳大利亚), Monash University(蒙纳士大学,澳大利亚)
背景
多任务学习(Multi-task Learning)、语义分割(Semantic Segmatation)、深度分析(Depth Estimation)、知识深化/精炼(Knowledge Distillation)
在基于神经网络的传感器信息提取方面,目前存在三个问题:
- 使用单一网络执行多个任务是很困难的(本文使用一个神经网络同时完成图像深度信息的计算和语义分割任务);
- 现有方法的实时性问题,这部分的相关工作(多任务网络的实时性问题仍然没有很好解决):
- Faster R-CNN: towards real-time object detection with region proposal networks (2015NIPS,MaskRCNN的前身,包含开源的MatLab和pytorch版本,)
- Squeezenet: Alexnet-level accuracy with 50x fewer parameters and <1mb model size (2016 开源代码)
- ICNet for real-time semantic segmentation on high-resolution images (2018ECCV 开源代码)
- 在单网络多任务的场景中,数据集上针对不同任务的标注数据会非常不均衡(比如图像深度信息和图像语义分割信息,两者的标注数据在数量上有较大差异)。
关于知识深化/精炼(Knowledge Distillation):引入与教师网络(teacher network:复杂、但推理性能优越)相关的软目标(soft-target)作为total loss的一部分,以诱导学生网络(student network:精简、低复杂度)的训练,实现知识迁移(knowledge transfer)。相关论文:
- Model compression, ACM SIGKDD, 2006 [34]
- Distilling the knowledge in a neural network, 2015 [35]
- Do deep nets really need to be deep? NIPS, 2014 [36]
- Fitnets: Hints for thin deep nets, 2014 [37]
Content
本文提出了一个实时的、能够同时完成图像深度分析和语义分割的、可以直接集成到诸如SemanticFusion等稠密+语义三维重建框架中的神经网络。
主要贡献:一节更比两节强! (A case of one being better than two!)
基础网络如下,其中Light-Weight RefineNet是作者之前的工作,基于CVPR2017的工作RefineNet做的轻量化改进,MobileNet-v2是Google专为移动和资源受限环境量身定制的新型神经网络架构。
- Light-Weight RefineNet:”Light-weight refinenet for real- time semantic segmentation” BMVC, 2018, 与本文是同一作者, 开源代码 [20]
- MobileNet-v2:”Inverted residuals and linear bottlenecks: Mobile networks for clas- sification, detection and segmentation” CVPR, 2018, Google, 开源代码 [21]
网络结构:
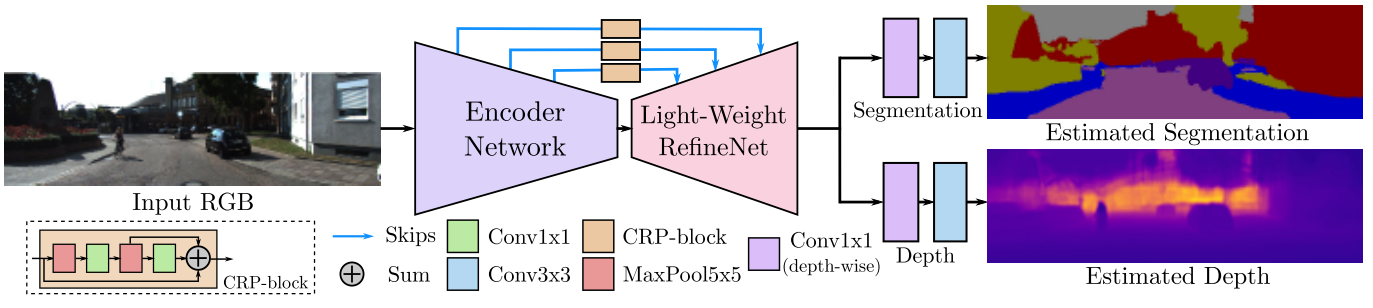
使用构建于MobileNet-v2分类网络上的Light-Weight RefineNet作为骨干网,该网络在输入图像大小为640 × 480时计算量14 GFLOPs,为进一步降低计算量,作者将最后的CRP block中的1*1卷积替换为分组卷积(Grouped Convolution),使其降低为6.5 GFLOPs (Giga Floating-point Operations Per Second, 每秒10亿次的浮点运算数)。
在上述Light-Weight RefineNet结构之后,网络分成两个预测任务,分别使用1x1的depthwise卷积和3x3的普通的卷积。
对于多任务模型,需要标注的数据含有每种任务的标签才能训练。对于两种任务T1和T2,假设只有少部分数据被标注了两种标签,对于样本数量更多的只有其中一类标签的数据,引入一个更加强大的专家模型(expert model),计算其在另一任务中的预测结果作为合成ground truth数据。训练的时候,使用合成ground truth数据先预训练网络,然后再使用拥有两种真实标签的ground truth对网络进行fine-tune。
代码:
实验
NYUDv2数据集:含有1449图像同时含有语义和深度标注(795幅训练集,654幅验证集),同时又有超过300000幅图像有深度标注。作者引入的专家模型是Light-Weight RefineNet-152 语义分割模型,其在验证集上的精度是44.4% mean iou。制作完合成语义标注后,使用大的含有合成标注的数据集预训练,然后在795图像的小数据集上fine-tune。
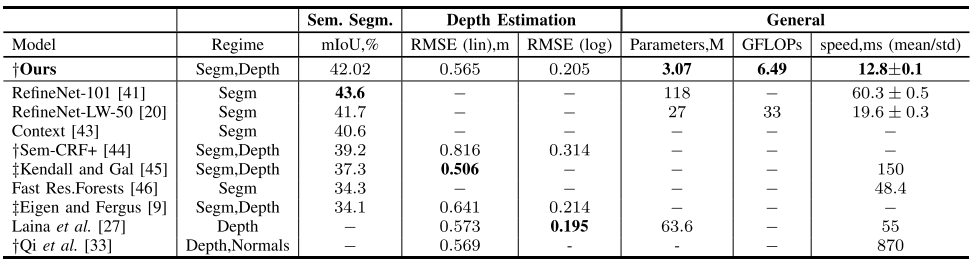
KITTI数据集:仅146幅图像有语义标注(100幅训练46幅测试),同时有20697幅图像有深度标注(20000幅训练,697幅测试),他们之间没有同时被标注了语义和深度的数据。作者使用在CityScapes数据集上训练的ResNet-38模型作为语义专家模型给20000仅有深度标注的图像预测语义标签,使用本文提出的网络架构在20000幅具有深度标注的图像上训练的深度估计模型,然后给100幅仅有语义标注的图像预测深度标签。按照上面的方法,现在大库上预训练,再在100幅图像的小库上fine-tune。

这两个任务甚至比目前state-of-the-art的大型网络都达到了更好的结果。参数量仅2.99M,而且在1200*350的图像上一帧计算时间仅需要16.9毫秒。
Stereo Vision-based Semantic 3D Object and Ego-motion Tracking for Autonomous Driving (ECCV2018 港科大)
OpenSource
无
Lab
港科大 栗培梁 (VINS-mono 二作)
Content (部分解读来自网络)
提出了一种基于双目相机,追踪自动驾驶环境中相机运动和3D语义对象的方法。
系统结构:
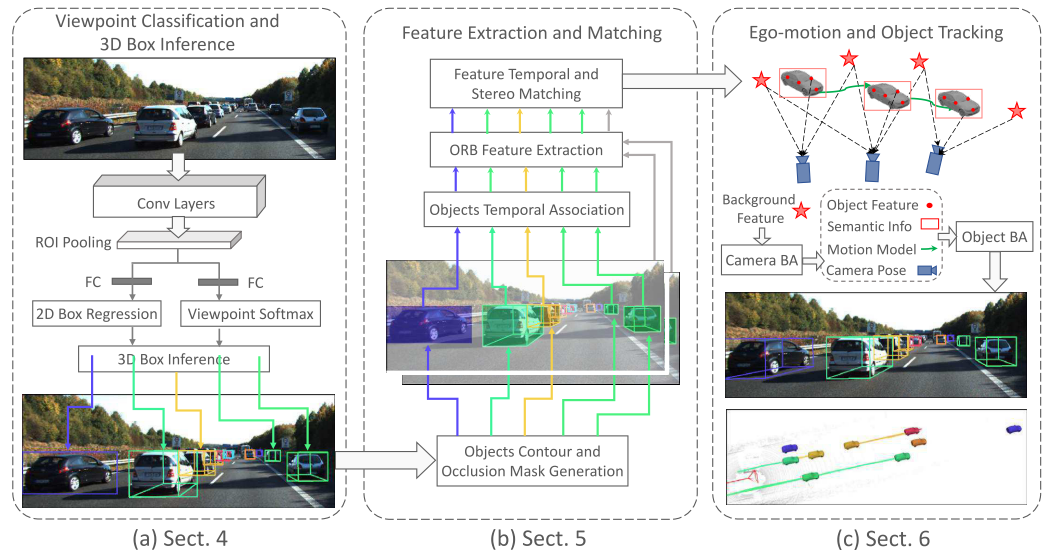
第一部分通过标准的Deep Learning方法进行2D Detection和视角分类,并通过相机模型,预测出初始的3D框;第二部分通过提取ORB特征和鲁棒匹配,完成双目深度估计与时序追踪;第三部分,也是整个文章的核心,通过SLAM中常用的Bundle Adjustment技术,联合优化自身位姿、每个车辆的位姿和状态,得到最终结果。
第一部分:主要参考了《3d bounding box estimation using deep learning and geometry》(CVPR2017),基本思想是通过预测2D框以及不同的观测视角,同时假设2D框能够紧密包围3D框,在给定视角,相机内参和车辆dimension的情况下,最紧的3D框和水平旋转角度可以直接通过线性方程组解出。这里做了很强的假设,也就是2D框完全准确,已经每种车辆的dimension是完全一致的,所以这个计算出的3D框只是作为后续操作的初始值,在第三部分中,还会重新优化这4个自由度的变量。
第二部分:主要任务是建立起可靠的local feature匹配和帧间关联。帧间关联和双目深度估计都使用了比较成熟的方案或简单的baseline。由于在第一步已经有了初步的距离估计,在双目匹配的过程中可以缩小匹配范围以提升结果。local feature这里使用的是经典的ORB feature。对于每个特征点,分别在左右眼和时序上进行匹配,后用RANSAC做outlier去除。
第三部分:整个文章中最重要的部分,把Bundle Adjustment (BA) 引入到了整个的位姿状态精调中来。这部分优化分为两个步骤,第一部分(Camera BA)是利用前面得到的背景中的匹配的点,联合优化自身相机位姿,以及在上一步匹配过的背景特征点坐标来优化重投影误差,这是在SLAM和SfM中的经典BA。通过这一步,可以得到相对准确的自身位姿为下一步使用。第二部分(Object BA)是针对每一辆车,充分挖掘2D和3D之间关系,以及各种约束。这部分BA分为4个loss term,联合优化了每个车辆自身的位姿,大小,速度和方向盘转角以及在上一步得到的ORB特征点的对应3D位置,下面分别介绍这4部分:
- 特征点一致性loss:求特征点对应的3D位置经过各种投射变换之后能够在它在2D图像上的坐标对应。文中分别对于左眼和右眼图像计算了loss,以左眼为例:
- 首先,作者假设车辆是一个刚体,也就意味着在帧间匹配得到的特征点,在车辆坐标系下的相对位置是不会随时间变化。
- 第一步变换,将特征点的3D位置f由车体坐标系转换到世界坐标系。
- 将世界坐标系内的f转换到相机坐标系。
- 将相机坐标系中的f通过相机内参矩阵投影回2D图像。
这样就可以计算这两者之间的一个差值,作为loss function。对于右眼,计算方法类似,只不过需要使用双目标定的外参,将左眼相机坐标系转换到右眼相机坐标系中,其余一致。
-
3D框与2D框一致loss:此项和第一部分的原理是类似的,区别在于,在这部分中,车辆的dimension和车辆的位姿被同时作为优化变量联合优化,而不是像第一部分中,车辆的dimension固定。所以通过加入这个term解决了在第一步中由于dimension不准确导致的错误估计。
-
车辆动力学模型loss:除了车辆位姿,我们在自动驾驶中还会关注车辆的状态,包括速度和方向盘转角,这对于后续的车辆意图估计等任务有着极大的帮助。实际的车辆当然不可以抽象成一个无规律的质点的运动,所以在这个loss中,作者使用了一个车辆动力学模型来描述当前时刻与前一时刻的位姿和状态之间的关系。这个动力学模型来源于原论文引用[27]。除了位姿之外,这个loss里还引入了车辆速度、方向盘转角以及车辆轮距(可以从车辆大小的出)作为优化变量。
-
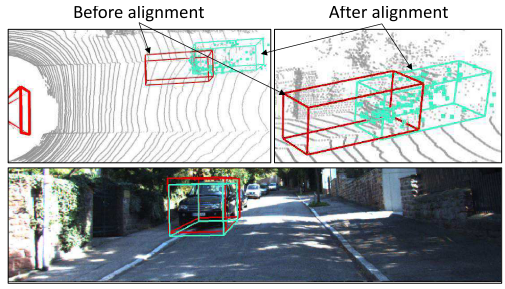
点云对齐loss:首先,这里的点云并不是指LiDAR点云,而是指从双目中恢复出来的点云。这个loss的意义在于约束每辆车的特征点的3D位置可以落在对应车辆的3D框内(minimize the distance of the feature points and their corresponding observed surface)。
点云对齐结果:
实验
在实验中,作者使用了KITTI数据集,分别对ego-motion和object localization&pose估计进行了比较。在ego-motion中,作者对比了经典的ORB-SLAM,由于这个方法能够很好地去除由于移动物体带来的特征点匹配失败,在一些车辆较多的复杂场景中取得了较大的提升。在object motion&pose中,由于前述引入的诸多先验和约束,对比baseline也有了较大提升。
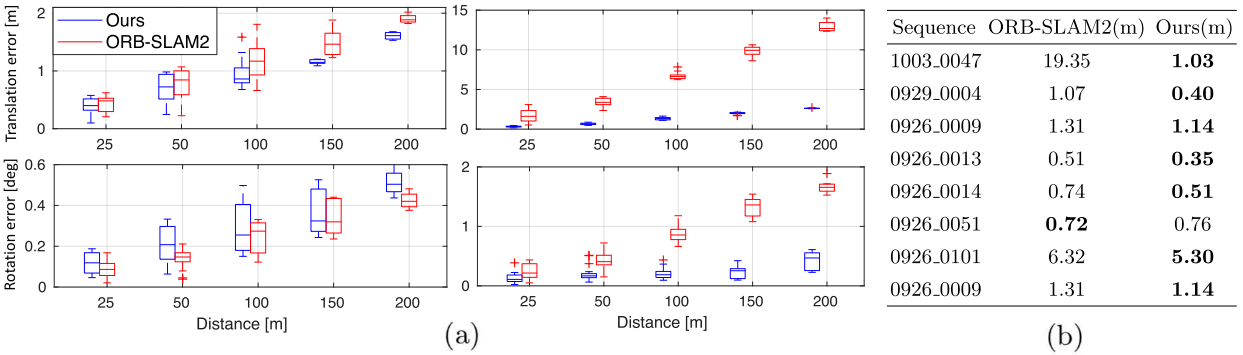
定性对比:

Stereo R-CNN based 3D Object Detection for Autonomous Driving (CVPR2019 港科大)
OpenSource
Lab
港科大 栗培梁 (VINS-mono 二作)
Content
Long-term Visual Localization using Semantically Segmented Images (ICRA2018)
OpenSource
无
Lab
Content
A variational feature encoding method of 3d object for probabilistic semantic slam(IROS2018)
OpenSource
无
Lab
Content
Detect-SLAM: Making Object Detection and SLAM Mutually Beneficial (2018WACV)
OpenSource
Lab
Content
SIVO : Semantically Informed Visual Odometry and Mapping (硕士论文, 2018, University of Waterloo, Canada,Pranav Ganti)
OpenSource
Lab
Content
其他相关论文
- “Improving RGB-D SLAM in dynamic environments: A motion removal approach,” RAS, 2017
- “Effective Background Model-Based RGB-D Dense Visual Odometry in a Dynamic Environment,” IEEE T-RO, 2016
- “On combining visual SLAM and dense scene flow to increase the robustness of localization and mapping in dynamic environments,” in ICRA, 2012
转载请注明原地址,魏鑫燏的博客: http://slowlythinking.github.io 谢谢!




