
ICRA2019论文列表(泡泡机器人)
此文包含较多图片,加载时间可能较长,请耐心等待:)
1.《RESLAM - A Real-Time Robust Edge-Based SLAM System》
OpenSource
Lab
Graz University of Technology, 奥地利格拉茨技术大学
Content
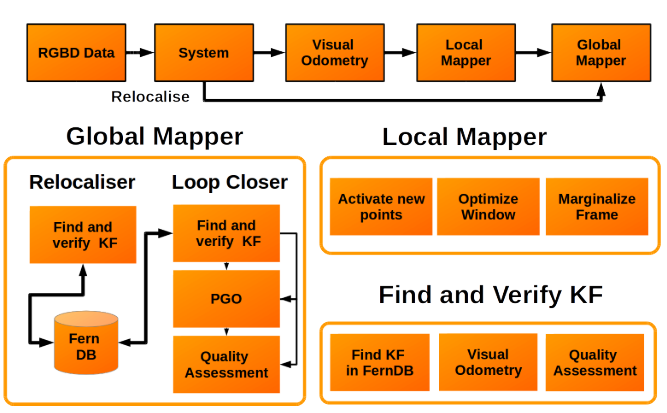
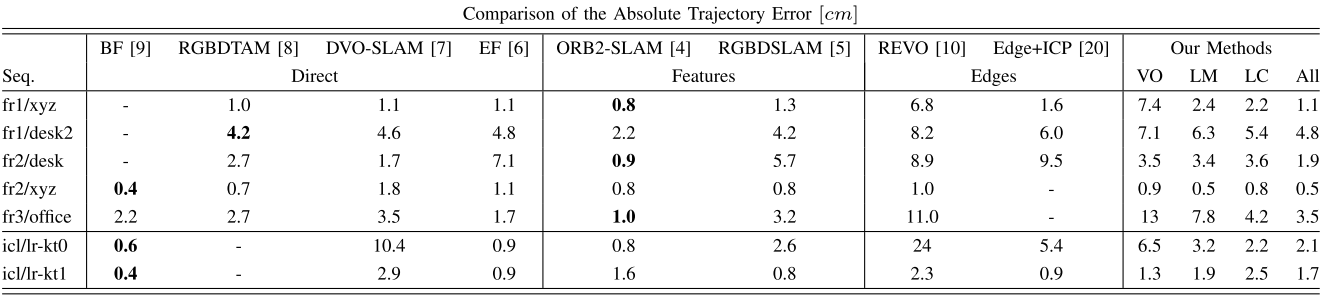
论文提出了一个基于边缘特征的RGBD SLAM系统,实现了局部滑窗的边缘深度优化,系统可以在CPU上实时运行(640*480px图像,30-35Hz,Intel i7-4790)。其主要创新在于实现了完整的基于边缘的SLAM系统(包括闭环检测)并开源了代码。
使用Canny算子来检测图像中的边缘,利用边缘的深度信息进行数据关联,闭环检测部分采用《Real-time rgb-d camera relocalization via randomized ferns for keyframe encoding》(2015TVCG)论文中的方法:对RGB图像下采样(得到40*30的图像),随机选择500个点,计算一个Fern descriptor,使用词袋法完成闭环检测。
系统结构:
实验结果:
2.《Real-time Scalable Dense Surfel Mapping》
OpenSource
Lab
香港科技大学
Content
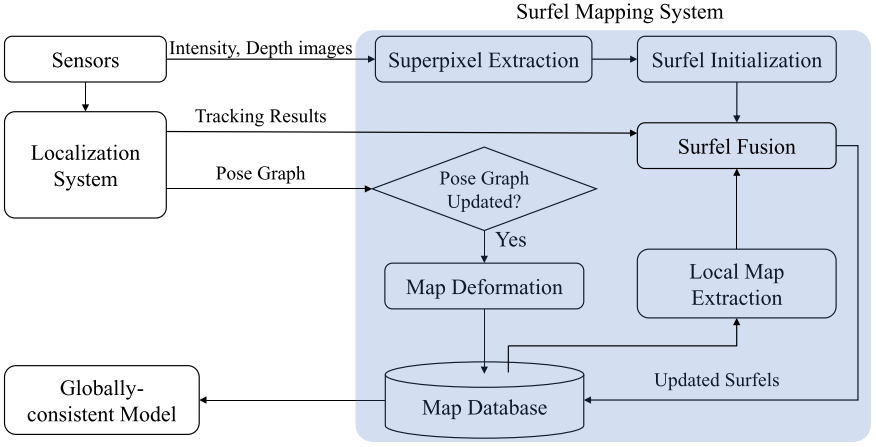
提出了一个基于表面(surfel)的dense RGBD SLAM,该系统不需要GPU即可运行(KITTI数据集上约为10Hz)。
系统结构:
3.《SLAMBench 3.0: Systematic Automated Reproducible Evaluation of SLAM Systems for Robot Vision Challenges and Scene Understanding》
OpenSource
PAMELA(A Panoramic View of the Many-core Landscape):由英国工程和自然科学研究委员会(EPSRC)资助的项目,PAMELA参与者包括帝国理工学院、曼切斯特大学和爱丁堡大学,slambench是它们开源的一套SLAM性能分析框架。参考:PAMELA的GitHub地址。目前仅开源了slambench1.0和2.0。
Lab
University of Manchester(曼切斯特大学),University of Edinburgh(爱丁堡大学,Imperial College London(帝国理工学院)
Content
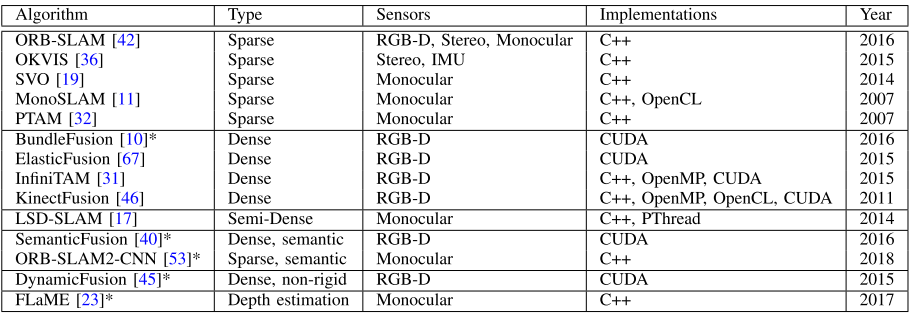
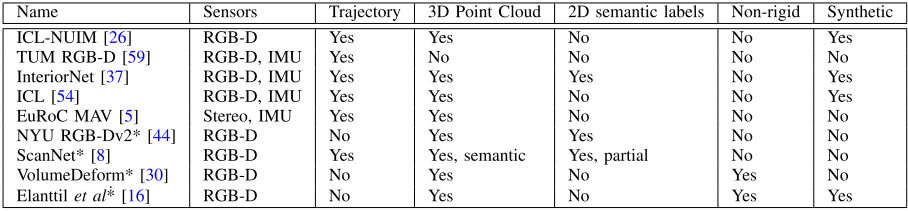
相比于SLAMBenchmark2,3.0有两个主要改进方向:动态场景(非刚体环境),基于深度学习的SLAM系统。新增了6个量化指标、4个数据集和5个SLAM算法。
新增了支持的SLAM算法和数据集(*号表示3.0新增的部分):
4.《SLAMBench2: Multi-Objective Head-to-Head Benchmarking for Visual SLAM》
本文为2018ICRA
OpenSource
PAMELA(A Panoramic View of the Many-core Landscape)项目中的一部分,开源地址。
Lab
University of Manchester(曼切斯特大学),University of Edinburgh(爱丁堡大学,Imperial College London(帝国理工学院),Stanford University (斯坦福大学)
Motivation
不同SLAM系统在不同数据集上的测试需要很多设置和环境配置,为了将这一测试工作系统化、减少冗余的分析工作,需要一个统一的基准测试程序,这一程序应该能够处理多种SLAM系统和多种数据集。
Content
SLAMBench2是一个SLAM性能测试基准,同时支持开源和闭源的SLAM系统。支持Ubuntu 14/16、 Fedora 24/25/26/27、 OS X 和Android平台;能够得到SLAM运行过程中的以下量化指标:精度、运行时间、内存占用和能耗;目前实现的特定SLAM系统用例(use-cases):efusion, infinitam, kfusion, lsdslam, monoslam, okvis, ptam, orbslam2, svo;目前支持的数据集:ICL-NUIM, TUM RGB-D和EuRoC MAV。
具体贡献:
- 用于不同SLAM系统的性能测试的开源框架;
- 提出的开源框架能够处理已有的9种SLAM算法;
- 便于集成新的SLAM系统和数据集(dataset-agnostic, plug and play algorithms)。
系统结构:
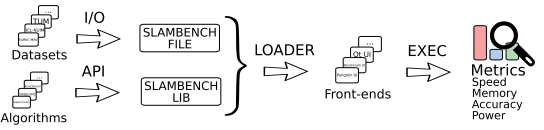
四个部分:
- I/O: 为统一不同数据集和SLAM系统中的数据格式,定义了一个通用的输入数据格式(包括ground truth、数据时间戳、图像、深度值等)和通用数据格式向其他特定SLAM系统数据格式的转换工具。
- API: 将特定SLAM系统的输入输出与SLAMBenchmark2连接起来的接口。共有6个API。
- Loader: 调用API,完成SLAM系统的运行。
- User Interface: 显示接口,利用Pangolin库实现。
论文价值:
- 开源的基准程序,可用于对比测试;
- 设计思路。
问题:
这类通用对比系统难以分析特定SLAM系统的运行细节,比如ORB-SLAM中存在关键帧,其他一些系统中没有,所以SLAMBenchmark中没有对关键帧相关指标的分析。所以在系统对比时可用,但在特定SLAM系统设计过程中使用难度较大。
5.《A Monocular SLAM System Leveraging Structural Regularity in Manhattan World》
本文为2018ICRA
OpenSource
项目主页(包含代码)
Lab
武汉大学遥感与信息工程学院
Content
文中提出的系统先使用已有的方法来估计出相机位姿和三维地图(《PL-SLAM: Real-time monocular visual SLAM with points and lines》中的方法),然后使用提出的基于平行、垂直、共面约束的优化策略来对估计出的相机位姿和三维地图进行进一步的优化。具体贡献:
- 提出了一个新的利用平行垂直约束的旋转矩阵优化策略;
- 一个新的利用共面约束的平移向量优化策略;
- 基于平行、垂直、共面约束的高效三维地图优化策略。
6.《3D Keypoint Repeatability for Heterogeneous Multi-Robot SLAM》
OpenSource
无
Lab
University of Southern California(南加州大学),NASA支持项目
Content
在异构多机协同SLAM(Heterogeneous Multi-Robot SLAM,比如搭载双目摄像头的无人机和搭载激光雷达的无人车)中,三维点云注册具有很大挑战,因为不同设备获取的点云具有较多不同的性质。如下图所示,同样一个场景(a),激光雷达获取的点云(b)和双目摄像头获取的点云(c)具有很多不同特性:双目获取的点云更稠密、误差更大、视角更小、包含错误的天空上的点。

这篇文章分析了常用的五种三维特征点检测算法在以上场景中的性能(作者认为本文是第一篇对比分析SLAM/VO应用中三维特征点检测算法性能的论文),主要分析了以下内容:
- 五种三维特征点检测算法在不同传感器获取的点云中寻找重复点/匹配点的能力;
- 在不同姿态下获取的点云中寻找重复点的能力;
- 对双目获取的点云和激光雷达获取的点云同时处理时的实时性;
分析的五种特征点检测算法:Harris3D, NARF, ISS, KPQ和KPQ-SI。前三种在PCL库中有对应实现,后两种使用C++编码实现。
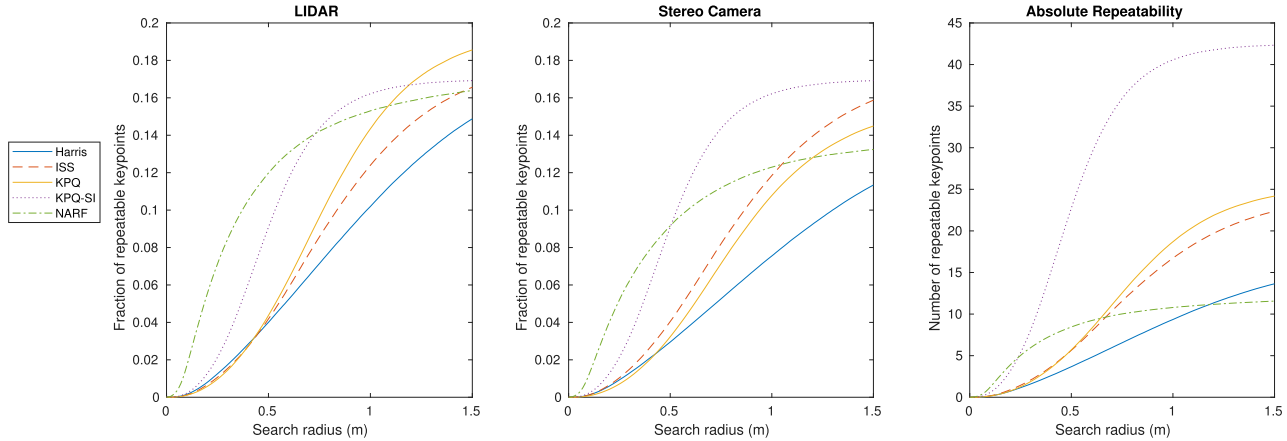
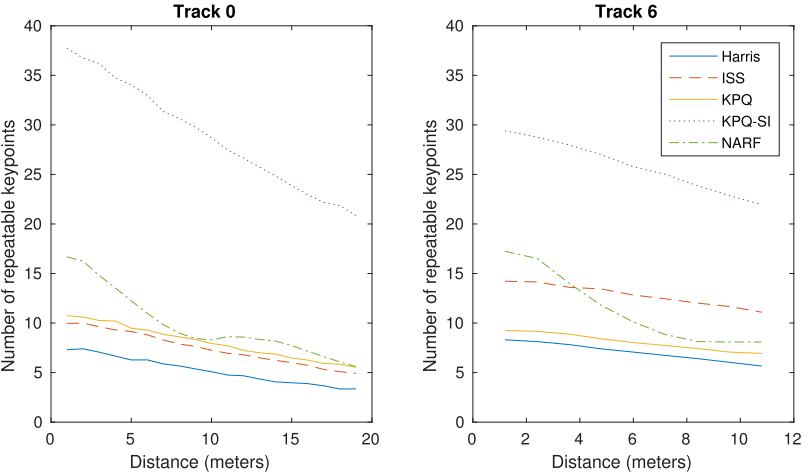
结论:相对而言,NARF和KPQ-SI算法能够找到最多的重复特征点,这两种算法能够提取足够的重复点以完成不同传感器点云的注册,其中KPQ-SI算法获取了最多数目的重复点,但是它的计算效率最低。
三维特征点数目:

同一姿态下不同传感器获取的三维特征点匹配性能/重复程度(左图为激光雷电点云上检测特征点,然后在双目点云上寻找匹配点的比例,中间图在双目点云上做相同处理,右图为两种点云间匹配点的数目,横坐标为搜索半径):
不同姿态下不同传感器获取的三维特征点匹配性能/重复程度(左右图为不同场景,横轴表示两个姿态间的距离,纵轴表示不同姿态下不同点云间的重复点/匹配点数目):
三维特征点检测时间(单位:秒):

7.《A Comparison of CNN-Based and Hand-Crafted Keypoint Descriptors》
OpenSource
无
Lab
University of Alberta(阿尔伯塔大学,加拿大)
Content
文章对比了三类二维特征点描述子的性能,主要关注光照变换和视角变化两种应用场景,所分析的三维特征点描述子为:
- 非机器学习方法(hand-crafted solutions):本文选择了SIFT和ROOT-SIFT;
- 预训练方法(pre-trained CNN):将AlexNet、VGG16、ResNet101、DenseNet169等CNN网络的不同层作为特征点描述子(由于这些层的长度往往超出了通用描述子长度,在选定层后加上一个最大池化层来得到最终的描述子);
- 训练方法(trained CNN):DeepDesc、L2-Net、CS L2-Net和HardNet等专用于特征生成的CNN网络方法。
目前大家并不关注预训练方法与其他两种方法的对比,已有的类似工作使用的数据集也很小,因此本文视图完成这一分析。
所使用的数据集(HPatches):
《Hpatches: A benchmark and evaluation of handcrafted and learned local descrip- tors》(CVPR2017)
实验结果:
1.预训练方法中选择的网络和作为特征点描述子的层:

不同层的性能(mAP):
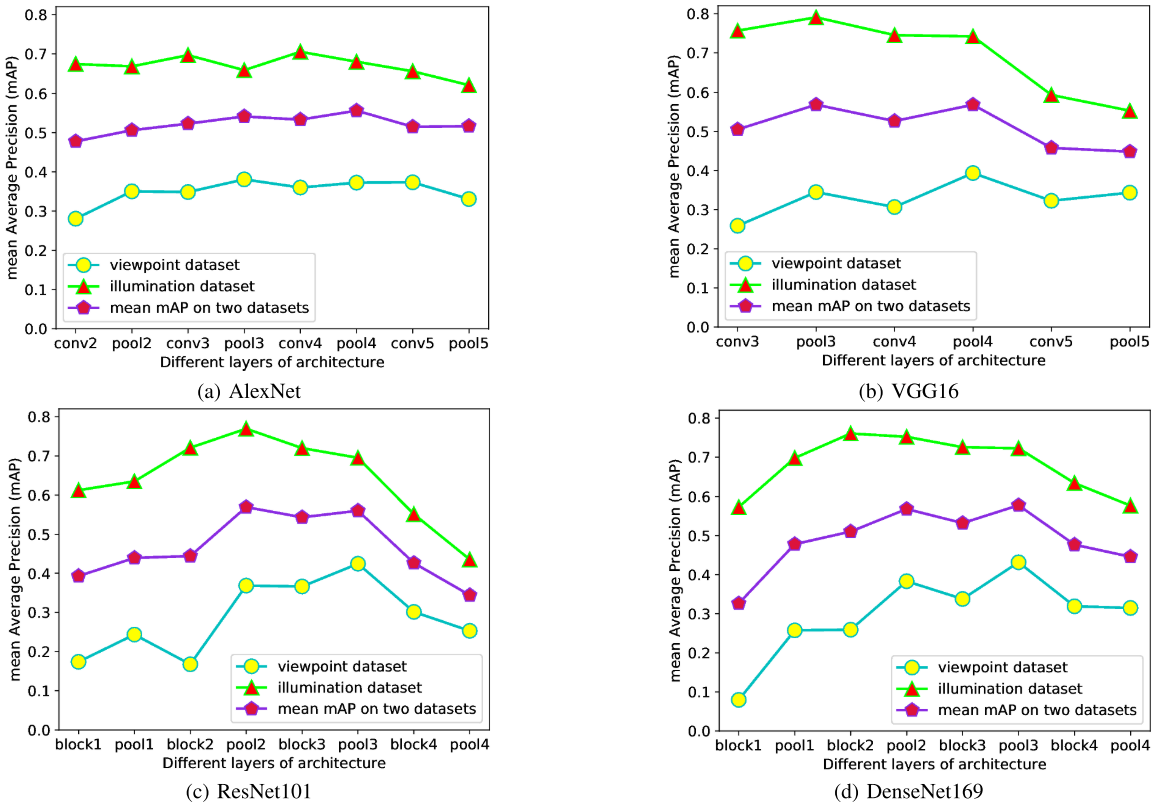
2.三种不同方法的性能:
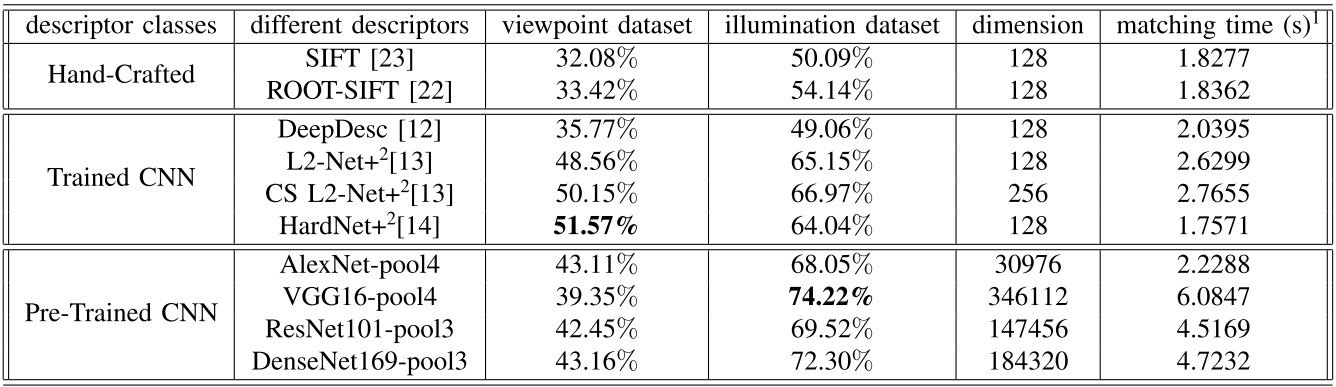
结论:Trained CNN方法在视角变换的场景下效果最好并且总体性能超过非机器学习方法,Pre-Trained CNN方法在光照变换的场景下效果最好。
8.《A-SLAM: Human in-the-loop Augmented SLAM》
OpenSource
无
Lab
American University of Beirut(贝鲁特美国大学)
Content
提出了一个基于Gmapping的、应用于增强现实领域的激光SLAM系统。特色:利用人的反馈交互来提升SLAM性能。
具体方法:通过HoloLens眼镜,用户可以编辑地图,即确定地图中哪些是障碍物区域,哪些可以通行,如下图(a:用户界面;b:操作过程;c和d:人为干预的地图):

核心:地图由Occupancy Grid Maps(OGM)表示,其中每个单元包含一个占据概率(0~1),表示这个单元是否被障碍物占据,未探索的区域值为-1,因为系统使用了这个地图,用户就可以很方便地参与进地图编辑,从而实现人机交互。
实验:没有量化结果,只有人参与与否的建图情况示例和路径规划结果。
9.《A Linear-Complexity EKF for Visual-Inertial Navigation with Loop Closures》
OpenSource
无
Lab
University of Delaware(特拉华大学,美国)
Content
想解决的问题:如何在MSCKF框架中加入闭环检测模块。一个简单的解决方法就是将闭环发生时的关键帧作为系统状态 $X$ 的一部分,在更新过程优化这些关键帧的状态,然而这会导致计算复杂度为 $O(n^2)$ ,其中 $n$ 为系统状态的维数 $dim(X)$ 。
针对以上问题,作者使用Schmidt-KF (SKF)来解决这一问题,SKF来自以下论文:
《Application of state-space methods to navigation problems》(1966)
具体而言,在滤波更新过程中,计算卡尔曼增益时,所有与关键帧相关的项首先被变换为一个单独的项,称为Schmidt-Kalman gain,此项在卡尔曼计算公式中直接取0。而主要的系统计算量减小就在此处。
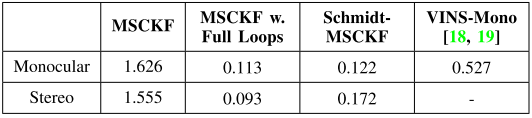
跟踪精度(RMSE):
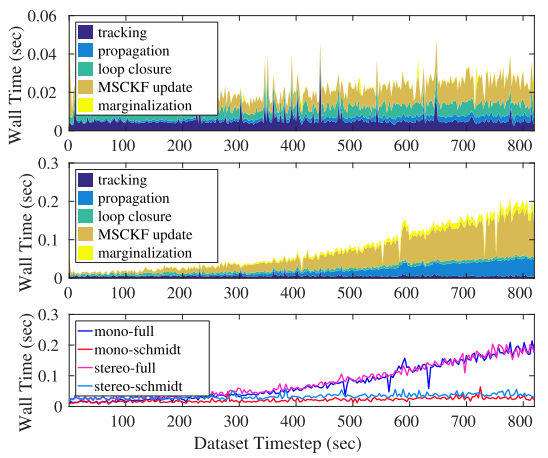
运行时间(上图:文中系统;中图:MSCKF;下图:文中系统的整体执行时间):
10.《A Unified Framework for Mutual Improvement of SLAM and Semantic Segmentation》
OpenSource
无
Lab
达闼科技(cloudminds)
背景
问题:SLAM应如何处理动态场景。核心思想是将动态物体探测出来,早期使用光流法等非机器学习方法来判断动态物体,近期基于机器学习的图像分割算法被用到了SLAM领域,相关的工作有以下一些,本文思路与[2]及其相似。
- 《Mask-SLAM: Robust feature-based monocular SLAM by masking using semantic segmentation》(2018CVPR)
- 《Detect-SLAM: Making Object Detection and SLAM Mutually Beneficial》(2018WACV)
- 《MaskFusion: Real-Time Recognition, Tracking and Reconstruction of Multiple Moving Objects》(2018ISMAR 开源代码)
- 《Dynaslam: Tracking, mapping, and inpainting in dynamic scenes》(2018 IEEE RAL 开源代码)
Content
结合vSLAM和语义分割,综合提升两个任务的计算性能。核心思想:使用语义分割结果来提升vSLAM位姿分析精度(通过识别和处理移动和潜在移动物体实现),使用vSLAM得到的三维位姿提升语义分割性能(使用三维位姿来优化语义分割结果)。
系统结构:
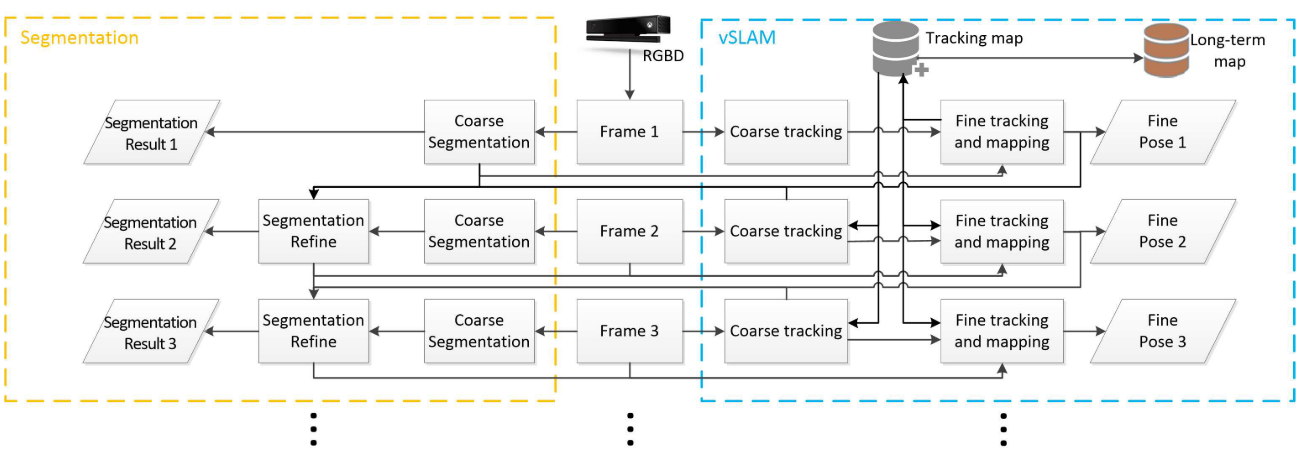
- 语义分割网络:FCIS(《Fully convolutional instance- aware semantic
- segmentation》2016),在MS COCO数据集上训练。 vSLAM:ORB-SLAM2。
用语义分割结果提升vSLAM性能:这部分较为简单,FCIS输出分割区域、背景区域及分割区域类别,对于人、车等潜在移动类别,不使用这部分区域对应的像素点来计算位姿,这样的操作可以提升SLAM系统的稳定性,个人感觉尤其是在关键帧选择部分,一旦关键帧中动态物体过多,传统ORB-SLAM2肯定会迅速崩溃,而这个方法解决了此问题。
用vSLAM结果提升语义分割结果:这部分更简单,得到前后两帧位姿,文章假设两件事情:1.视频帧率够高,两帧之间动态物体没动;2.前一帧优化过的语义分割结果是准确的。有了这两个假设,就把后一帧的像素点投影到当前帧,对比两帧的分割结果,以后一帧结果为真值。当前帧没分出来的补上,分错的去掉。
实验结果
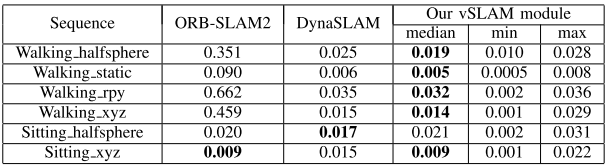
vSLAM结果(其中DynaSLAM就是参考文献4的开源SLAM):
作者另外自己弄了个数据集对比与FCIS的分割效果,意义不大,不放结果了。
总结
相比于DynaSLAM,SLAM精度提升效果不明显,利用位姿来改进语义分割效果这块,感觉还很粗糙。
11.《A Variational Observation Model of 3D Object for Probabilistic Semantic SLAM》
文笔和数学功底很强
OpenSource
无
Lab
Seoul National University(首尔大学,韩国)
背景知识
变分推断(Variational Inference):在概率模型中,我们常常需要近似难以计算的概率分布,在贝叶斯统计中,所有的对于未知量的推断(inference)问题可以看做是对后验概率(posterior)的计算,而这一概率通常难以计算。简要来说,变分推断的核心思想是将概率推断问题转化为优化问题,即面对一个难以求解的概率分布,首先,提出一族关于隐藏变量的近似概率分布,然后从这一族分布中找到一个与真实的后验分布的KL Divergence最小的分布。
可参考《Variational Inference: A Review for Statisticians》(2018Journal of the American Statistical Association)
Content
在语义SLAM中,语义特征的一般都具有高纬度特性,这导致在语义特征的优化过程中难以处理,具体表现在高纬度的语义特征变量的概率分布函数很难得到(The probabilistic distribution of the object with complex 3D shape is intractable),本文利用变分推断方法来得到语义SLAM中三维特征观测模型的变分似然(variational likelihood),具体使用了《Auto-encoding variational bayes》中的方法。
为什么要获取特征观测模型中变量的后验分布?当后端优化过程中不考虑这个后验分布时,后端极易被前端的错误关联数据影响。
相似工作有《A variational feature encoding method of 3d object for probabilistic semantic slam》(IROS2018)
主要参考了《Auto-encoding variational bayes》(2013, 代码, 此篇文章拥有多种框架的实现)
实验
目标检测部分使用了《Yolo9000: Better, faster, stronger》(2017CVPR)论文中的方法,使用IMU数据得到真实尺度(IMU数据不参与位姿计算与优化),初始位姿计算使用八点算法,数据集使用KITTI和TUM。
实验结果:

12.《Are We Ready for Autonomous Drone Racing? The UZH-FPV Drone Racing Dataset》
OpenSource
Lab
University of Zurich(苏黎世大学,瑞士), ETH Zurich(苏黎世联邦理工学院,瑞士)
Content
针对无人机竞速,及类似的应用场景,提出了一个快速、高机动性运动无人机场景下的视觉+IMU的数据集。数据类型包括:鱼眼相机、Event Camera(动态视觉传感器,由苏黎世大学在几年前首先提出)、IMU、6自由度位姿真值(由一个激光跟踪系统测量得到)。共包含两个场景(室内+室外),共27段视频。
与其他VI数据集的对比:
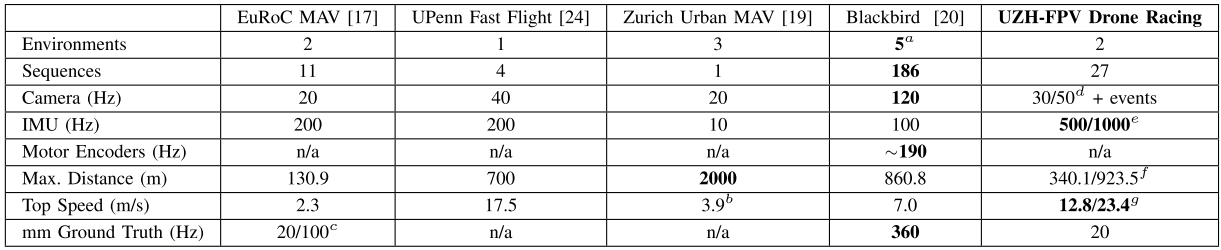
实验场景:

13.《Beyond Photometric Loss for Self-Supervised Ego-Motion Estimation》
OpenSource
Lab
The Hong Kong University of Science and Technology(港科大),腾讯
背景
目前已有的自监督VO/SLAM系统中一般将像素灰度误差作为系统中的“监督项”,但这存在一些问题:
- 由于光线反射、动态物体等因素,光度一致性假设在真实场景中不成立;
- 即使是针对基线极小的相机运动来说,光度变化也会引起较大误差(佐证:目前的单目深度估计算法最多只能使用连续的三帧进行训练,一旦增加到五帧,误差会迅速增大)。
相关论文:
- 《Geonet: Unsupervised learning of dense depth, optical flow and camera pose》(2018CVPR)[47]
- 《Unsupervised learning of depth and ego-motion from video》(2017CVPR)[50]
- 《Unsupervised learning of monocular depth estimation and visual odometry with deep feature reconstruction》(2018CVPR)[48]
- 《Unsupervised learning of depth and ego-motion from monocular video using 3d geometric constraints》(2018CVPR)[29]
- 《Supervising the new with the old: learning sfm from sfm》(ECCV2018)[21]
Content
系统概览( $D$ 为深度图):
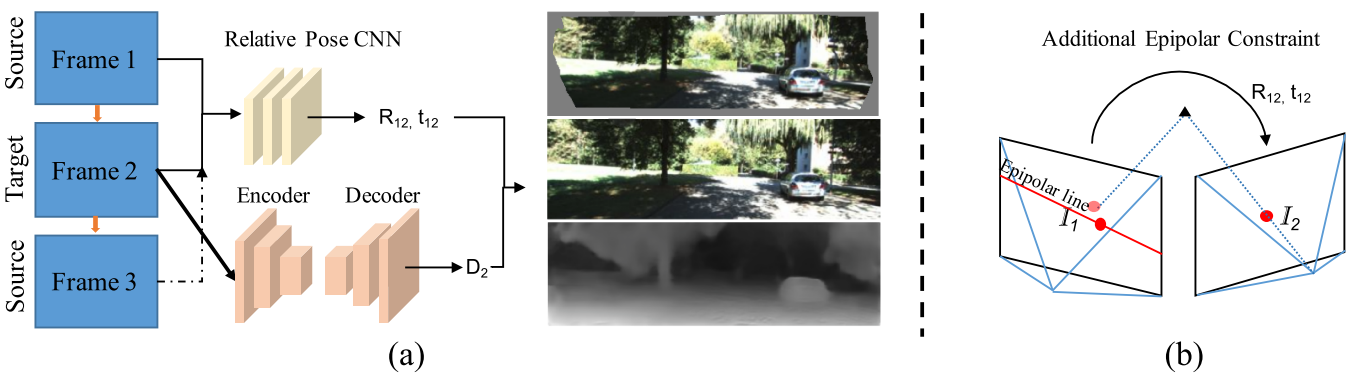
损失函数:
\[L_{total} = M(P_M)*L_{img}+\omega_sL_{smooth}+[\omega_gL_{geo}]+[\omega_pL_{pose}]\]解释:
- $L_{img}$ : 传统光度误差项,具体计算过程:输入两帧,由深度网络算出其中一帧 $F$ 的深度图 $D$ ,即可以得到 $F$ 中一点 $p$ 的深度值 $D(p)$ ,根据相对位姿网络可以得到两帧之间的相对位姿 $T$ ,根据 $T$ 和 $D(p)$ 可以得到点 $p$ 在另一帧上的投影点 $p_T$ , $p_T$ 和另一帧上的图像点 $p’$ 之间的光度差值就是待优化化的误差。
- $L_{smooth}$ :一个根据深度图梯度和图像灰度梯度计算出的平滑项,是为了解决低纹理区域深度数据断层等问题而设立的,也是传统方法常用的误差项。
- $L_{geo}$ :本文的核心创新点,利用对极几何计算出的误差项,即 $F_1$ 帧中某点在 $F_1$ 帧中的极线与 $F_1$ 中对应点的距离(点线距离)
- $L_{pose}$ :参考文献[5],将几何约束集成到已有的机器学习模型中,这里提出了两类位姿: Direct-Weak-Pose,使用特征点匹配对+PnP算法得到的位姿;Prior-Weak-Pose,使用常用相对位姿CNN网络计算的位姿, $L_{pose}$ 就是这两种位姿的差值。
- $M(P_M)$ :一个及其简单的去除动态物体影响的阈值方法,丢掉 $L_{img}$ 中较大的1%。
- $\omega$ :权重。
实验
使用SIFT描述子进行特征点提取和匹配、使用双目版本ORB-SLAM2中采用的PnP算法(EPnP+RANDOM算法)进行Direct-Weak-Pose位姿计算,使用ResNet-50作为深度图计算网络,使用参考文献2中的网络进行Prior-Weak-Pose(相对位姿)计算。
实验模式:
- Pairwise-Matching: $w_g = 0.001, w_p = 0$ ;
- Prior-Weak-Pose: $w_g = 0, w_p = 0.1$ ;
- Direct-Weak-Pose: $w_g = 0, w_p = 0$ ,注意这个模式下只训练深度网络, $L_{img}$ 中的相对位姿由PnP算法得到(而非CNN网络)。
实验结果:
文中系统的对比-深度图精度:

不同系统的对比-深度图精度:
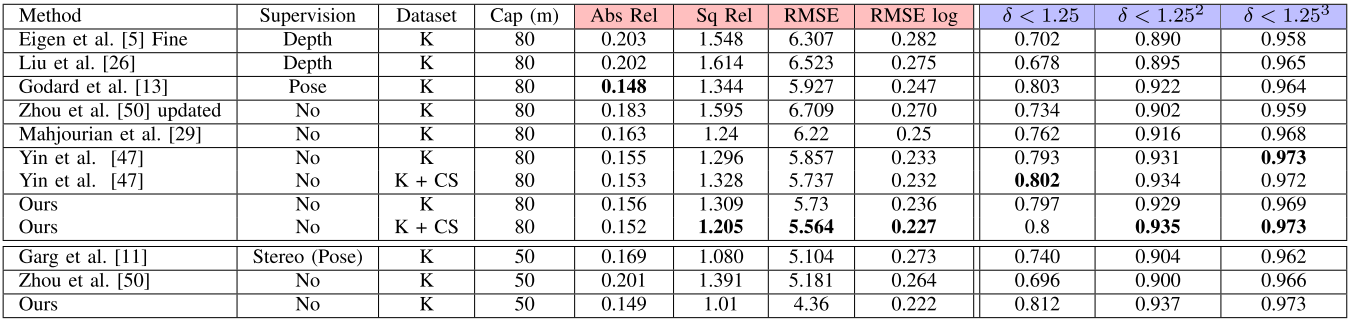
不同系统的对比-位姿精度(绝对轨迹误差ATE):
总结
文中给出了一个使用图像特征的神经网络VO系统的实现案例,并给出了开源代码。表明了集成对极几何约束到代价函数中是能够提升系统性能的,该系统目前还存在以下问题:文中未给出计算时间,但从其采用SIFT描述子来看,一定不能实时;该文看起来是光度误差与几何误差的简单集成,虽然最后效果超过了文献[5],但是直观看来文献[5]对图像特征的使用更适合与光度误差网络的集成;实际性能仍远低于ORB-SLAM2。
14.《Characterizing Visual Localization and Mapping Datasets》
OpenSource
Lab
Imperial College London(帝国理工学院,英国),University of Bath(巴斯大学,英国)
背景
目前已有的SLAM评测工具主要针对SLAM算法的不同性能指标,比如位姿精度、运算时间等,但是随着SLAM算法的涌现,目前SLAM数据集的数目也在快速增加,怎么判断我的SLAM算法应该使用哪一个或者那些数据集来测试?因此,需要一些指标来表示数据集的特性。
已有的SLAM算法评测框架:
- 《SLAMBench 3.0: Systematic automated reproducible evaluation of SLAM systems for robot vision challenges and scene understanding》(ICRA2019)[4] 同一年的同一会议竟能互相引用
- 《A benchmark comparison of monocular visual-inertial odometry algorithms for flying robot》(ICRA2018)[5]
- 《Embedding SLAM algorithms: Has it come of age》(RAS2018)[6]
Content
针对背景中的问题,文章的创新点如下:
- 提出了针对SLAM数据集的统计指标,与特定SLAM算法无关,用于表示数据集的跟踪难度;
- 提出了新的人工合成的数据集,包括16个视频,包含RGBD和IMU数据。数据集包含两个室内场景,场景为人工合成(建立三维模型,生成三维场景),位姿轨迹为真实采集,包括地面机器人、人、无人机三种移动方式,通过位姿轨迹来从三维模型中渲染出照片,生成数据集。
####SLAM数据集的统计指标
核心是Wasserstein distance,Wasserstein distance描述的是两个概率分布之间的距离(为什么不适用KL散度和JS散度的原因:在非高斯分布中,Wasserstein距离能够提供一个更合理的结果(Reasonable Answer))。
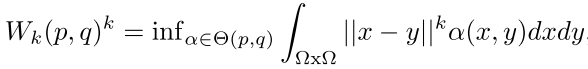
| 其中 $O(p,q)$ 为 $p$ 和 $q$ 分布组合起来的所有可能的联合分布, $\alpha(p,q)$ 为这些联合分布的概率,对于某一个特定的联合分布,可以从中采样得到一个样本 $x$ 和 $y$ , $ | x-y | $ 表示这对样本的距离, $inf$ 表示对所有可能值的下界。 |
SLAM问题的本质是一个最大后验概率估计(MAP)问题,其中的似然部分可以表示为这样的概率形式:
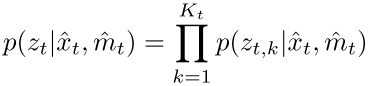
其中 $\hat{x}t$ 表示 $t$ 时刻的预测位姿, $\hat{m}_t$ 表示 $t$ 时刻的地图(包含 $K_t$ 个路标点), $z{t,k}$ 表示 $t$ 时刻第 $k$ 个路标点的观测值。
因此,数据集的统计指标可以定义为:
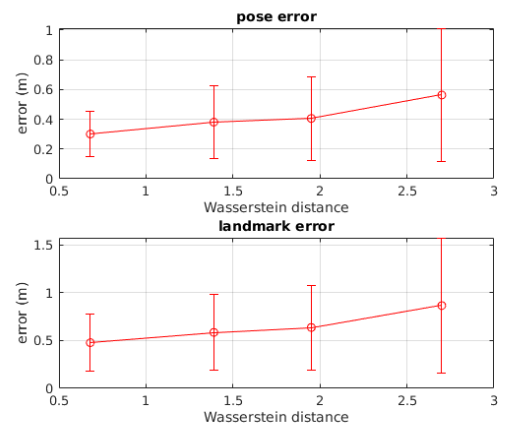
\[\omega(t)=W_2(P_t,P_{t-1})\]即两个连续的时刻间后验概率的距离,当这个距离的中值或者均值越大,就表明数据集的难度越大(difficulty score)。具体计算中,根据位姿及路标点的真值、高斯分布假设、噪声来构造以上函数中的变量分布的期望和方差,完成计算。
实验结果(EKF-SLAM在四个不同Wasserstein距离场景中的位姿误差和路标点误差):
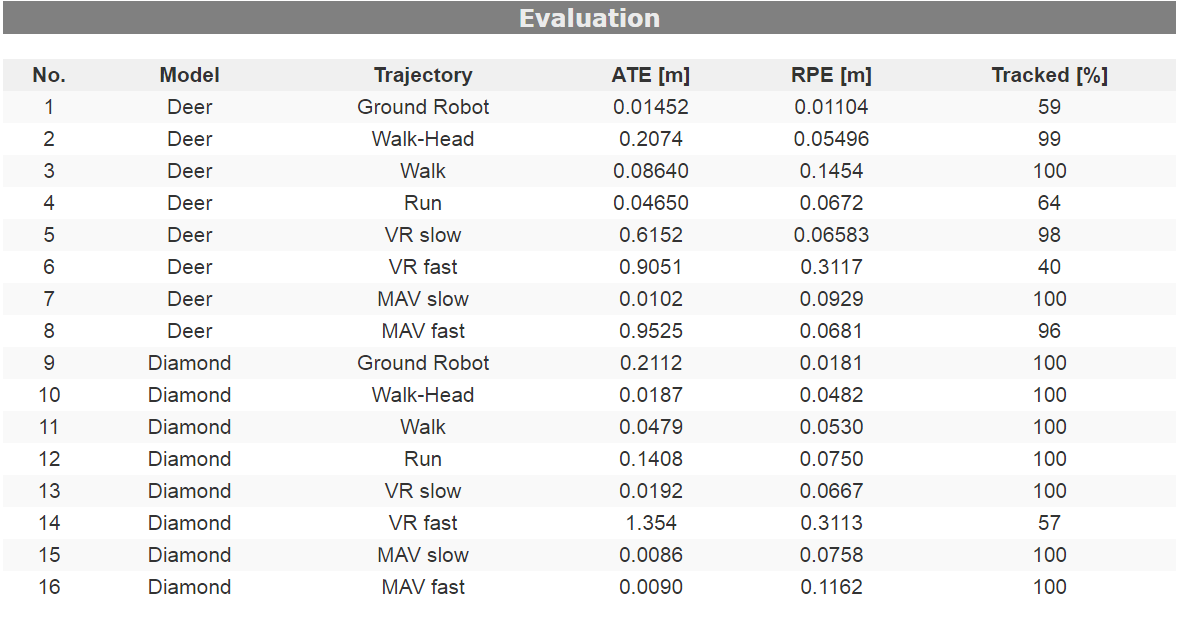
数据集基本信息,以及RGB-D ORB-SLAM2的运行结果:
15.《Closed-loop MPC with Dense Visual SLAM - Stability through Reactive Stepping》
OpenSource
无
Lab
University of Nice Sophia Antipolis(尼斯-索菲亚·昂蒂波利斯大学,法国),University of Montpellier(蒙彼利埃大学,法国)
背景
类人机器人的运动控制方面,常用的是Linear Inverted Pendulum(LIP)和Model Predictive Control(MPC)算法,后者目前是主流方法。
MPC控制是一种高级的进程控制(process control)方法。用来控制进程使它满足一些限制条件。MPC算法是一个大类,其中包括广义预测控制(Generalized predictive control, GPC)、动态矩阵控制(Dynamic Matrix Control, DMC)等。MPC的三要素:内部预测模型,滚动优化,反馈校正。
- 预测模型:根据被控对象的历史信息和未来输入信息,预测系统的未来输出响应;
- 滚动优化:通过某一性能指标的最优化求解未来有限时刻的最优控制率;
- 反馈校正:首先检验对象的实际输出,再通过实际输出对基于模型的预测输出进行修正并进行新的优化。
零力矩点(Zero-Moment Point, ZMP): 在地面上存在一点 $P$ ,使得与地面平行轴方向的,由惯性力( $F=ma$ )与重力( $G=mg$ )所产生的净力矩为零的点。ZMP实际上是机器人重力与惯性力的合力在地面上的投影点。如果ZMP落在机器人的支撑区域中,则机器人不会摔倒。
参考:
- LIP:《Introduction to Humanoid Robotics》(Springer, 2014)[1]
- MPC:《Walking without thinking about it》(IROS2010)[2];
- MPC: 《A reactive walking pattern generator based on nonlinear model predictive control》(RAL2017)[3].
- MPC: 《Intrinsically stable MPC for humanoid gait generation》(RAS2016)[12]
Content
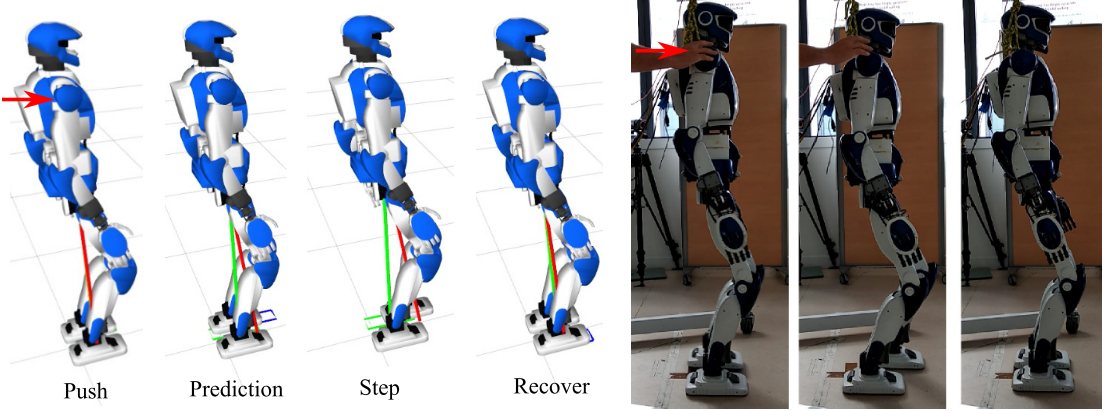
目前双足机器人步态规划过程中使用MPC算法时,一般没有考虑当前机器人状态,这会导致机器人无法对当前外部干扰做出及时反应。本文使用SLAM算法和机器人运动传感器(压力/扭矩)来分析机器人当前状态和环境信息,并将这些信息集成到MPC算法中,是机器人能对外部干扰(如被推挤)做出反应。示意(第二步和第三步是通过感知环境和自身状态来恢复平衡的过程):
文中同时使用RGBD-SLAM算法(30Hz)和VICON动作跟踪系统(100Hz)来计算位姿,示意图如下:
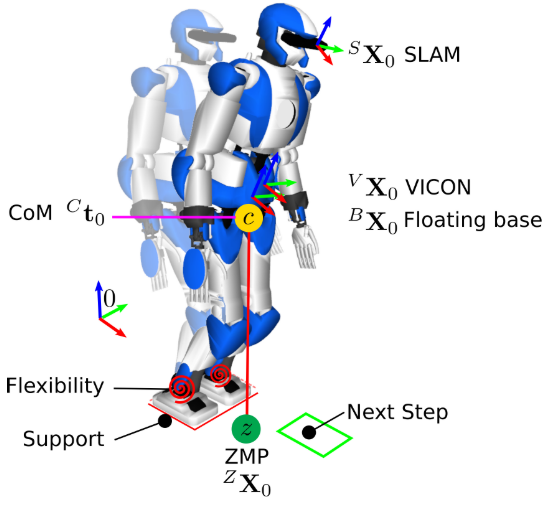
整个系统通过实时计算机器人的质心(COM)和ZMP来判断机器人的总体状态,一旦ZMP超出支撑范围,通过SLAM和VICON返回的当前浮动基(floating base)位置和速度,MPC算法会规划返回平衡状态的参考ZMP,并进行相应控制。具体实现中MPC算法构建了几个优化函数:基于目标移动位置、方向和当前机器人ZMP位置、速度的优化函数、ZMP和COM的稳定性约束函数、ZMP必须处于机器人支撑区域的约束函数、运动时双脚不能碰撞的约束函数。
实验设备:HRP-4(类人机器人,日本Kawada公司,151 cm,39 kg)
实验(横轴为时间,左图中194.7s时ZMP超出阈值,机器人有摔倒风险,MPC算法开始规划步态):
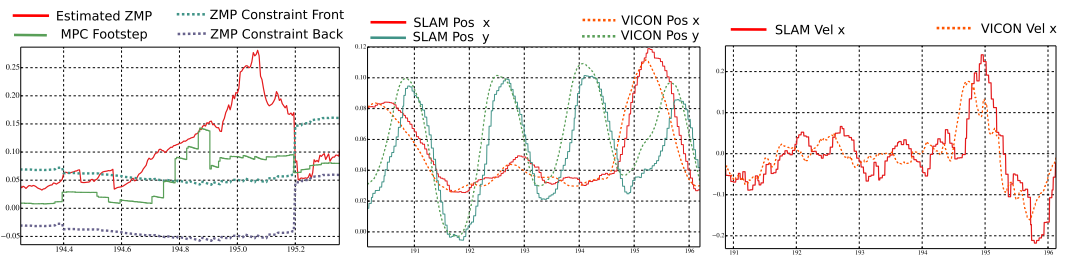
总结
- 系统考虑了外部的实时干扰,能及时回正。
- 文中仅使用了SLAM算法提供的相机位姿,由此来计算当前机器人浮动基位置,未使用环境地图,额外使用了VICON系统来提供位置真值,SLAM算法在当前实现中作用有限;
- SLAM算法为30Hz,VICON系统为100Hz,控制系统为200Hz,在浮动基位置未返回时,当前MPC算法仍然使用不考虑外部干扰的LIP模块来计算,系统间帧率配合有一些问题。
16.《CNN-SVO: Improving the Mapping in Semi-Direct Visual Odometry Using Single-Image Depth Prediction》
OpenSource
Lab
University of Alberta(阿尔伯塔大学,加拿大),Universiti Putra Malaysia(博特拉大学,马来西亚)
Content
SVO存在的问题:SVO在初始化新的地图点时将平均深度设置为参考帧的平均深度,具有很大的不确定性。大的深度不确定性会带来以下两个问题:
- 极线特征匹配误差增大;
- 更多的深度测量值才能收敛到真实的深度值。
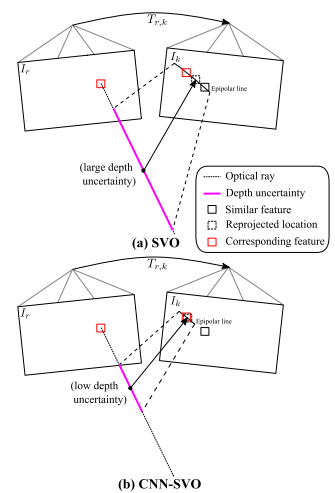
采用单一图像预测网络去初始化深度的均值和方差,从而提升了SVO的建图效果,主要改进了三维点生成时的深度估计部分。
系统使用了《 Unsupervised Monocular Depth Sstimation with Left-Right Consistency 》(2017CVPR)中提出的神经网络。
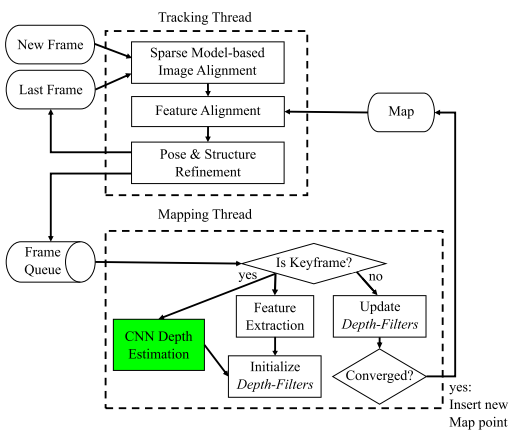
系统框架(CNN-SVO通过单一图像深度估计作为先验知识去获得均值和方差更小的深度滤波器):
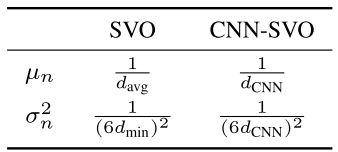
核心(改进每个三维特征深度滤波器的参数初值,使用CNN网络提供的值来初始化逆深度均值和方差):
在KITTI数据集上的实验结果:
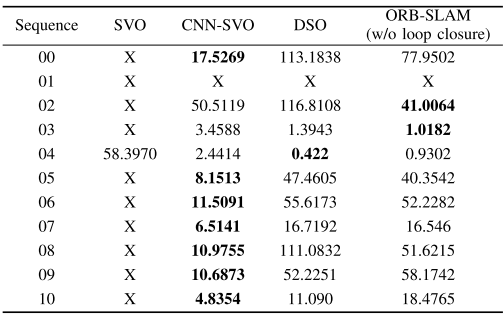
在Oxford Robotcar数据集上的实验结果:
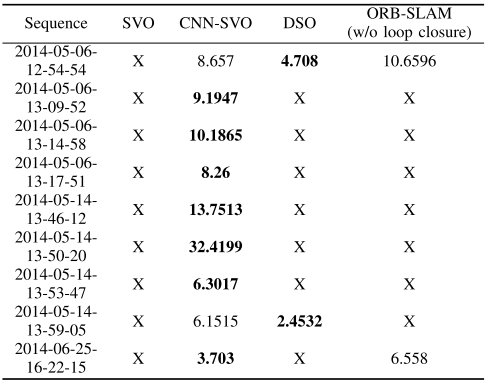
总结
- 优点:论文选择了SVO,这实际上是非常适合结合深度估计神经网络的一个VO系统,因为SVO原版中三维点的初始深度是通过平均深度值直接指定的,便于嵌入单目深度分析算法。之前的点线结合SVO也是这样,选择一个合适的改进算法非常重要。
- 缺陷:需要GPU(实验中使用NVidia GeForce GTX Titan X),运行时间较长:10fps(KITTI数据集),其中深度估计每帧需要37ms
17.《DeepFusion : Real-Time Dense 3D Reconstruction for Monocular SLAM using Single-View Depth and Gradient Predictions》
OpenSource
无
Lab
Imperial College London(帝国理工,英国)
背景
SLAM与深度学习结合的主要优势:
- 基于DL的单目深度信息可用于恢复尺度;
- 基于DL的单目深度信息可作为SLAM建图中的初始估计、提高系统精度;
- 基于DL的单目深度信息可作为SLAM建图中缺失地图(由于遮挡、SLAM系统自身缺陷等原因)的补充;
- 基于DL的语义识别可作为动态场景下SLAM建图的辅助手段。
具体实现上,可以总结出以下几个主流或合理方案:
- 利用机器学习辅助SLAM而不是相反(考虑端到端DL的精度和运算时间);
- 在建图线程,即关键帧而非普通帧上使用DL方式进行处理(运行时间考虑);
- 目前DL辅助SLAM中效果明显的方案主要有单目深度估计、尺度和动态场景。
- 在已有DL得到的深度、尺度和场景语义的前提下,将这些信息嵌入现有SLAM的方式还没有通用的方案,需要根据特定系统进行选择(如CNN-SVO关注位姿、本文和CNN-SLAM关注建图,都是较好的案例)。
相关论文:
- 《Single-view and multi-view depth fusion》(2017RAL)[20]
- 《Dense monocular reconstruction using surface normals》(2017ICRA)[21]
- 《Deep virtual stereo odometry: Leveraging deep depth prediction for monocular direct sparse odometry》(2018ECCV)[22]
- 《DeepTAM: Deep tracking and mapping》(2018ECCV)[23]
- 《Deep depth completion of a single rgb-d image》(2018CVPR)[24]
- 《Scale recovery for monocular visual odometry using depth estimated with deep convolutional neural field》(2017ICCV)[25]
- 《Just-in-time reconstruction: Inpainting sparse maps using single view depth predictors as priors》(2018ICRA)[26]
- 《CNN-SLAM: Real- time dense monocular slam with learned depth prediction》(2017CVPR)[27]
Content
这篇文章的目标是使用基于神经网络的单目图像深度分析算法来辅助SLAM系统构建一个更准确的地图,同时得到真实尺度。
系统框架:

具体步骤:
- 使用ORB-SLAM2获取位姿的初始估计;
- 使用LSD-SLAM得到半稠密地图;
- 对于关键帧,使用改进后的U-Net(U-Net来自《U-Net: Convolutional networks for biomedical image segmentation》(2015MICCAI,开源代码)获取单目图像的深度、深度的对数的不确定性、深度梯度的对数、深度梯度的对数的不确定性(对U-Net进行改进以获取不确定性数值的方法来自《What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision?》(NIPS2017),开源代码),该网络在SceneNet RGB-D数据集上训练,训练时使用测试数据集中相机的焦距对深度值进行归一化处理,这保证后续能够得到真实尺度(这一步与CNN-SLAM类似)。
- 由于目前关键帧深度图中有网络预测的,也有LSD-SLAM计算的,所以需要进行全局一致性优化(本文与CNN-SLAM最大的不同):
解释:
- $c(d,s)$ : 优化目标函数
- $s$ : 尺度变量
- $d$ : 关键帧的深度图
- $c_{semi}(d,s)$ : 由LSD-SLAM计算的深度与当前深度值的差值(注意加入尺度变量)
- $c_{net}(d,s)$ : 由U-net预测的深度值与当前深度值的差值(注意其中包括网络输出的深度不确定性数值)
- $c_{grad}(d,s)$ : 待优化深度的像素点与邻近的四个点的深度梯度误差,误差计算中包含深度梯度(即当前点深度乘以深度梯度和距离应该等于临近点深度值),这一额外增加的项保持了整个关键帧图像内深度值的一致性,可以剔除一些外点。
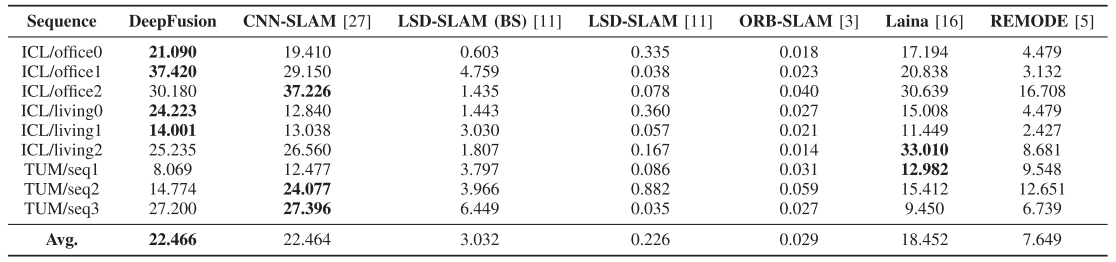
实验结果
重建效果(不同行表示不同场景,从左至右各列为:输入图像、真值、LSD-SLAM的半稠密图、U-net预测深度图、x轴方向的网络预测深度梯度、y轴方向的网络预测深度梯度、最终优化后的深度图):

各场景中不同算法得到的准确深度值占比(相对于GT),作者在这里解释为什么TUM上CNN-SLAM比本文的好:训练数据集不一样,训练数据集对SLAM中DL方法的应用有很大影响。
关键帧的各项处理时间(计算平台:Core i7-5820K CPU, GeForce GTX 980 GPU):

总结
- 这篇文章的Introduction很好玩,考虑地太全面以至于感觉像是在坑自己(但是这部分确实有较大的学习价值,因为写的很细):1. 稀疏特征的SLAM没有关注建图,机器人导航、密集重建等应用场景中不行;直接法SLAM能产生稠密地图,但对于遮挡和重复纹理场景性能很差;半直接法(LSD-SLAM)避免了上面的问题,但是只能产生半稠密地图(semi-dense);2. 单目SLAM不能得到真实尺度;VISLAM在加速度很小的运动情形中尺度很难观测;RGBD-SLAM中RGBD设备能耗大,不能在室外和强光下工作。
- 文章关注于建图,其实验结果可以说明两类方法融合时一致性优化的重要作用。
- 没有开源,但是整个过程比较详细,复现可能性较大,性能类似的CNN-SLAM目前也只有一个他人实现的代码,所以在DL辅助SLAM建图的方向,这篇+CNN-SLAM需要重点关注。
18.《Efficient 2D-3D Matching for Multi-Camera Visual Localization》
OpenSource
无
Lab
ETH Zurich(苏黎世联邦理工学院,瑞士),微软
背景
目前的视觉定位算法主流是基于三维结构的(Structure-based),该方法可分为两类:显示和隐式的(Explicitly and Implicitly),显示方法首先通过SFM方法获取一个稀疏的点云模型,然后为每一个三维点建立一个对应的图像描述子,当需要定位的图像输入系统时,对比图像中的特征点描述子和三维点的图像描述子,找到2D-3D的匹配对,使用PnP+RANSAC算法求解图像对应的相机位姿;隐式方法不使用描述子,直接将图像块对应到三维点云中,找到2D-3D的匹配对,后续同样方式处理。
隐式方法比显示方法的精度高,但难以处理大规模场景,相关论文:
- 《Learning Less is More - 6D Camera Localization via 3D Surface Regression》(CVPR2018)[4]
- 《On-The-Fly Adaptation of Regression Forests for Online Camera Relocalisation》(CVPR2017)[7]
目前的多相机定位系统主要关注的应用领域:
- 双目SLAM;
- 相机标定;
- 相机位姿分析。
Content
本文针对已有三维地图下,多相机定位的问题,提出了一套系统。系统模块主要包括2D-3D特征匹配和迭代的位姿分析(两个主要创新点)。系统框架:
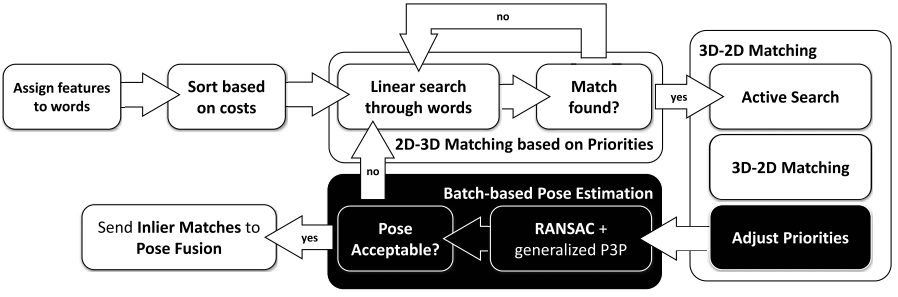
特征匹配部分基于SIFT特征和词袋法,使用了有序的主动搜索算法(来自论文《Efficient & Effective Prioritized Matching for Large-Scale Image-Based Localization》(2017PAMI),将原论文的算法扩展到了多相机的应用场景,首先,基于快速最近邻搜索,找到与单个特征对应的词袋中的word,然后,基于关联到同一个word的特征数目,对特征进行排序,关联特征数目越少的word表示对应的特征越独特,越有可能得到正确匹配,此时对这些特征进行线性搜索,同时为了选择不同视角的特征匹配(为了稳定的位姿分析),距离计算中加入了一个新的项:
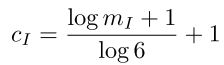
其中 $m_I$ 表示当前帧与地图中的帧 $I$ 匹配上的特征数目,匹配上的特征数目越多,当前帧中其他特征与 $I$ 中特征的距离就越大。
位姿计算,采用了迭代和并行算法:上述特征匹配和当前位姿计算是并行进行的,位姿计算使用RANSAC算法,停止的标准:当符合位姿猜测的特征匹配对数目超过15,并且在整个匹配对中占比超过20%。
扩展至VIO,作者将以上的匹配算法扩展到了已知初始位姿预测值(利用IMU数据)的情形,即实现了一个在已有三维点云地图中进行导航的VIO系统,后端使用图优化框架,利用Ceres库实现。
实验使用了两个数据集:One North和RobotCar Seasons,在One North上的实验结果(sunny和overcast表示两个典型场景,前者重复场景多,后者光照变化明显,prior是指知道相机位姿初始猜测值的结果):

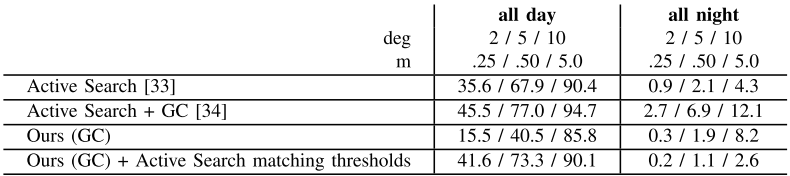
在RobotCar Seasons数据集上的结果(all day和all night表示两个场景,deg和m对应的是误差位姿的阈值,GC表示多相机版本,可以看到all day场景下,本文方法在误差阈值低时精度低于Active Search原版算法,在误差阈值高时精度更高):
转载请注明原地址,魏鑫燏的博客: http://slowlythinking.github.io 谢谢!




